


Ploomber provides an enterprise-grade platform for securely sharing your data and internal apps with everyone on your team or your customers.

Isolated network environment
Restrict access to trusted IP addresses
Secure database connection with fixed IP

Choose between SaaS or On-Premise
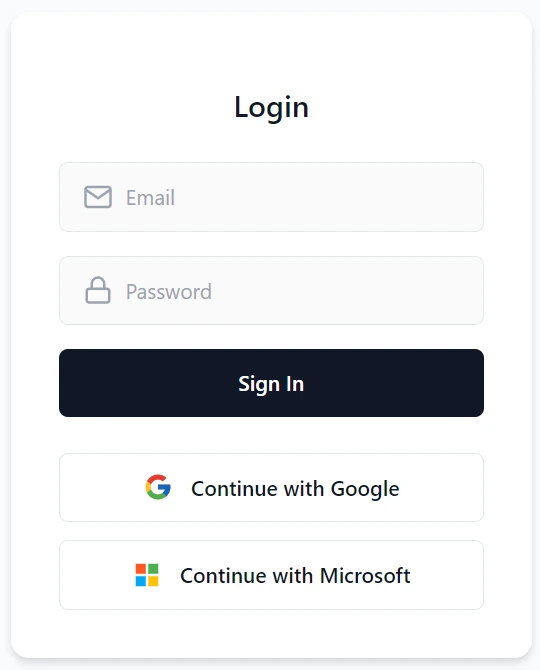
Add Enterprise-grade authentication without code changes.
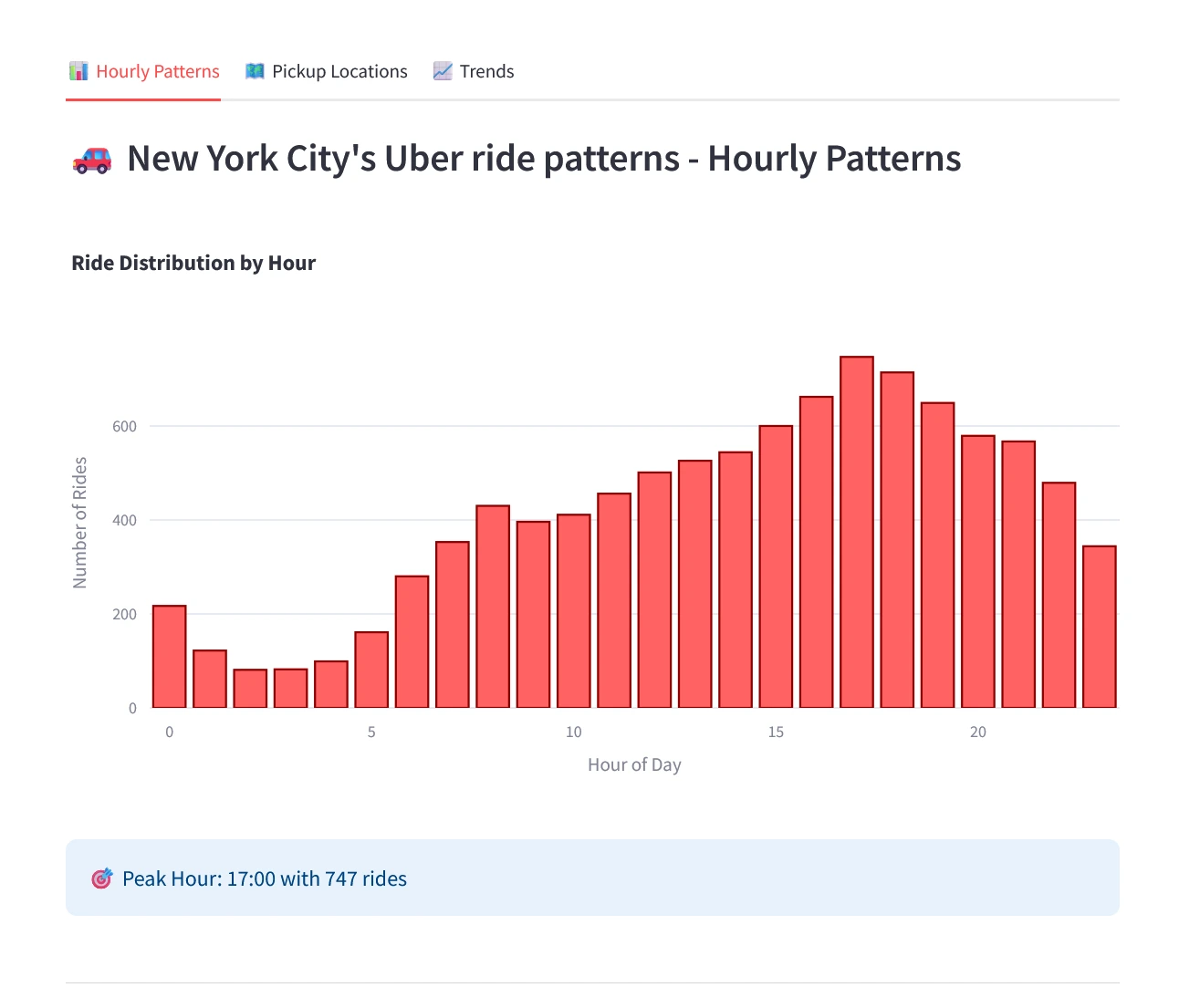
Monitor performance metrics with crystal clarity
→ Real-time insights
→ Understand customer behavior
Scale automatically during peaks or maintain fixed resources.
→ Automatic traffic-based scaling
→ Fixed resource mode
Serve your app from app.yourdomain.com or yourdomain.com
Choose your repository and get a complete production environment
Granular permission management for your applications
→ Role-based access control
→ Team-specific permissions
→ Customizable security policies
Test features in isolation with a dedicated preview environment for every PR
Bug in to production ? Simply Rollback







Ploomber dropped our dev time by 40%

Ploomber enabled faster iterations.

The best tool I've tried. Maximum return, 0 BS.
