


For the past couple of months, we’ve chatted with many Data Science and Machine Learning teams to understand their pain points. Of course, there are many of these. Still, the one that surprised me the most is how hard it is to get some simple end-to-end workflow working, partially because vendors often lock teams into complicated solutions that require a lot of setup and maintenance.
This blog post will describe a simple architecture that you can use to start building data pipelines in the cloud without sacrificing your favorite tooling or recurring high maintenance costs. The solution involves using our open-source frameworks and AWS Batch. Let’s get started!
AWS Batch is a managed service that allows users to submit batch jobs. AWS provides resources (e.g. spin up an EC2 instance) without extra cost (you only pay for the AWS resources used).
AWS Batch is an excellent service, but it still requires some setup to containerize your code and submit the jobs. Our open-source framework allows you to automate this process, so you can quickly move from the interactive environment you love (Jupyter, VScode, PyCharm, and others) to the cloud instantly.
If you haven’t heard of us, Ploomber is an open-source framework that allows data scientists and machine learning engineers to build modular pipelines from their favorite editor. We provide a simple approach for users to modularize their work without disturbing existing workflows.
When you’re ready to run experiments at a larger scale or deploy, you can quickly move to AWS Batch (we also support Kubernetes, Airflow, and SLURM as backends) with a single command. Our framework automates building the Docker image, pushing it to the container registry, passing data between tasks, submitting jobs to AWS Batch, caching results, and uploading artifacts to S3. Upon successful execution, you can download the results to analyze them locally.
In Ploomber, users typically declare their tasks in a pipeline.yaml file (although a Python API is also available). These tasks can be functions, notebooks, or scripts (note: we integrate with Jupyter to allow users to open .py as notebooks). Here’s an example:
tasks:
# a function that downloads raw data
- source: tasks.raw.get
product: products/raw/get.csv
# a function that generates features
- source: tasks.features.features
product: products/features/features.csv
# a parametrized script that trains multiple models
- source: scripts/fit.py
name: fit-
# each script run gets a different set of parameters
grid:
# generates 6 tasks
- model_type: [random-forest]
n_estimators: [1, 3, 5]
criterion: [gini, entropy]
# generates another 6 tasks
- model_type: [ada-boost]
n_estimators: [1, 3, 5]
learning_rate: [1, 2]
# each script run generates a model and a evaluation report
product:
nb: products/report.html
model: products/model.pickle
Once the pipeline.yaml is declared, users can orchestrate execution locally with:
ploomber build
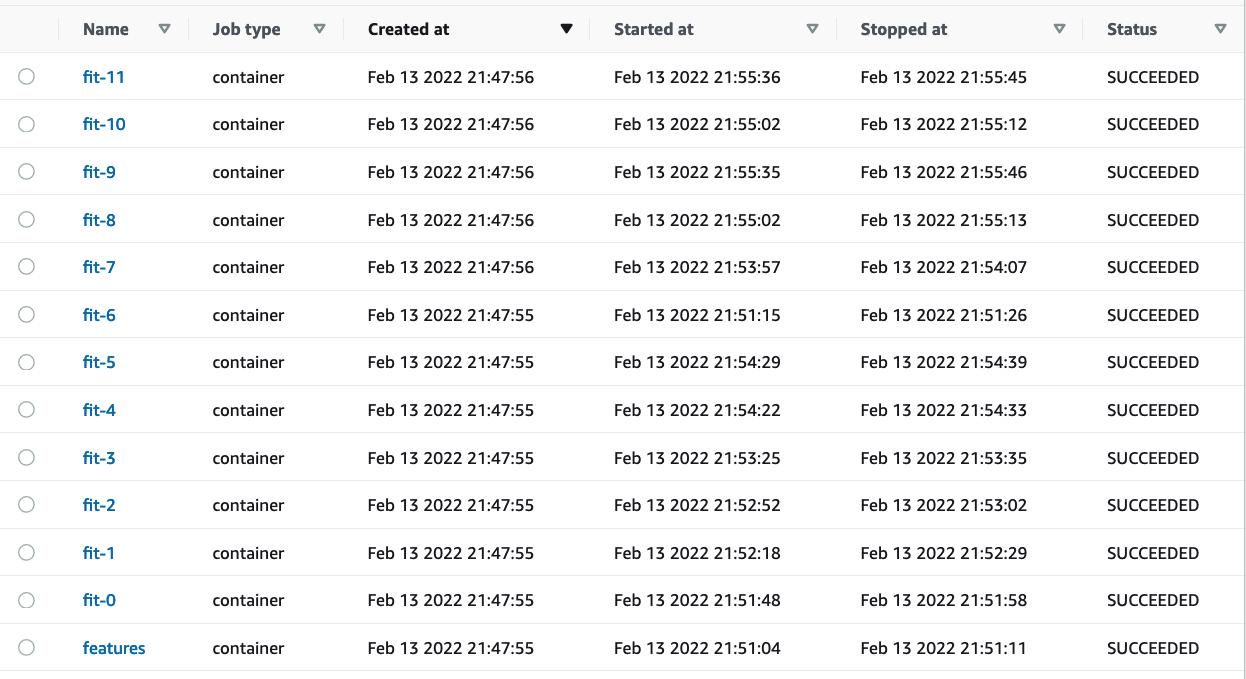
With a few extra steps, you can move your local pipeline to AWS Batch; here’s a screenshot of the 11 model training tasks (executed in parallel) after finishing execution on AWS:
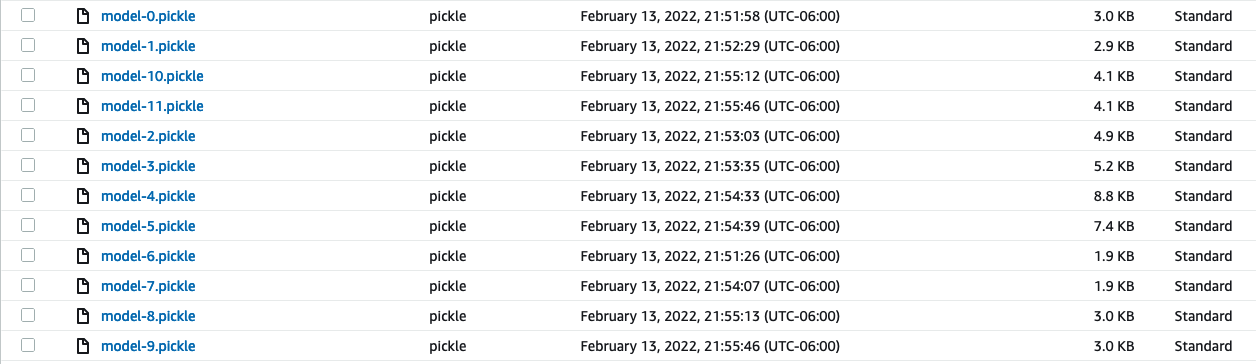
And here’s the output. The model files:
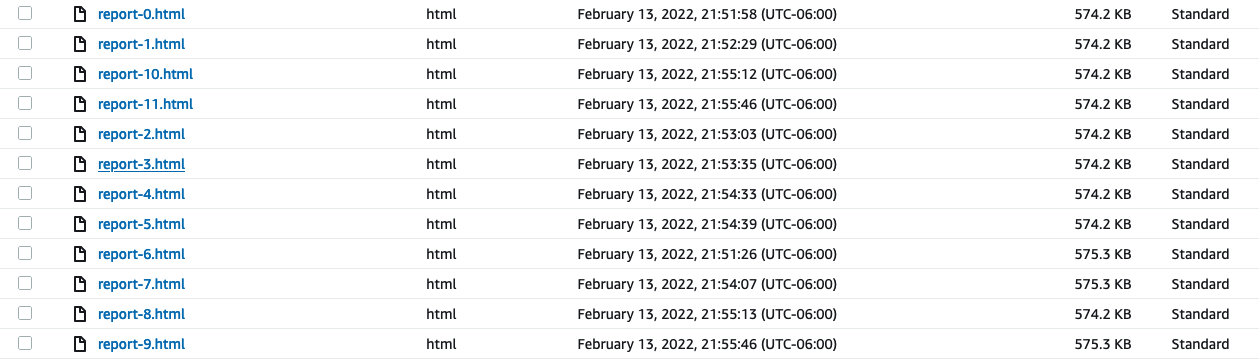
And an HTML report for each model:
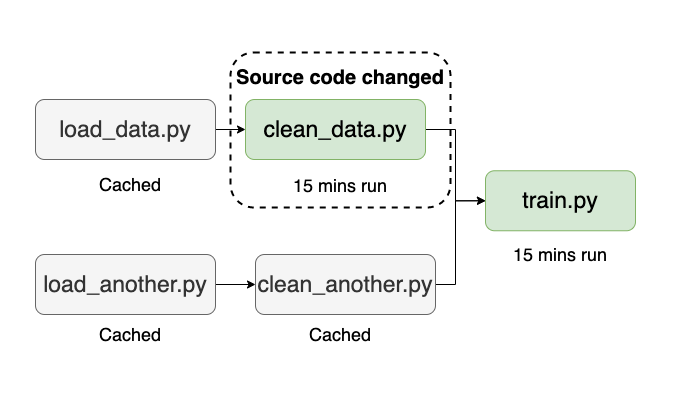
Data Science and Machine Learning are highly iterative. For example, you may want to tune pre-processing parameters, tweak some feature engineering transformations, or add a few diagnostic charts. It’s a waste of your time (and money) to re-run your pipeline end-to-end on each small iteration. To help you, Ploomber keeps track of source code changes. Hence, the next time you execute your workflow, it will only submit jobs whose source code has changed (and all downstream tasks) since the last execution, significantly speeding up iteration and reducing cloud computing time.
Run a Ploomber example:
# get ploomber
pip install ploomber
# ML pipeline example
ploomber examples -n templates/ml-basic -o ml-basic
cd ml-basic
# install dependencies
pip install -r requirements.txt
# run pipeline
ploomber build
Congrats, you ran your first Ploomber pipeline! Running the pipeline in AWS Batch requires just a few extra steps:
# package to export to aws batch
pip install soopervisor
# create config files
soopervisor add batch --backend aws-batch
Before submitting to AWS Batch, you need to configure the service from the AWS console and then configure your project. Check out our complete tutorial to learn more.
Once that’s done, you can submit to the cloud with the following command:
# submit to aws batch
soopervisor export batch
Ploomber + AWS Batch is the leanest way to start running Data Science and Machine Learning pipelines without infrastructure management. Since it allows you to build data pipelines with your favorite text editor, there is no need to refactor your code to run your workflow in the cloud, thus, reducing the development cycle allowing you to experiment faster.
Do you have any questions? Ping us on Slack!
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

