


As Data Science and Machine learning get wider industry adoption, practitioners realize that deploying data products comes with a high (and often unexpected) maintenance cost. As Sculley and co-authors argue in their well-known paper:
(ML systems) have all the maintenance problems of traditional code plus an additional set of ML-specific issues.
Paradoxically, even though data-intensive systems have higher maintenance cost than their traditional software counterparts, software engineering best practices are mostly overlooked. Based on my conversations with fellow data scientists, I believe that such practices are ignored primarily because they are perceived as unnecessary extra work due to misaligned incentives.
Data projects ultimate objective is to impact business, but this impact is really hard to assess during development. How much impact a dashboard will have? What about the impact of a predictive model? If the product is not yet in production, it is hard to estimate business impact and we have to resort to proxy metrics: for decision-making tools, business stakeholders might subjectively judge how much a new dashboard can help them improve their decisions, for a predictive model, we could come up with a rough estimate based on model’s performance.
This causes the tool (e.g. a dashboard or model) to be perceived as the unique valuable piece in the data pipeline, because it is what the proxy metric acts upon. In consequence, most time and effort is done in trying to improve this final deliverable, while all the previous intermediate steps get less attention.
If the project is taken to production, depending on the overall code quality, the team might have to refactor a lot of the codebase to be production-ready. This refactoring can range from doing small improvements to a complete overhaul, the more changes the project goes through, the harder will be to reproduce original results. All of this can severely delay or put launch at risk.
A better approach is to always keep our code deploy-ready (or almost) at anytime. This calls for a workflow that ensures our code is tested and results are always reproducible. This concept is called Continuous Integration and is a widely adopted practice in software engineering. This blog post introduces an adapted CI procedure that can be effectively applied in data projects with existing open source tools.
Continuous Integration (CI) is a software development practice where small changes get continuously integrated in the project’s codebase. Each change is automatically tested to ensure that the project will work as expected for end-users in a production environment.
To contrast the difference between traditional software and a data project we compare two use cases: a software engineer working on an e-commerce website and a data scientist developing a data pipeline that outputs a report with daily sales.
In the e-commerce portal use case, the production environment is the live website and end-users are people who use it; in the data pipeline use case, the production environment is the server that runs the daily pipeline to generate the report and end-users are business analysts that use the report to inform decisions.
We define data pipeline as a series of ordered tasks whose inputs are raw datasets, intermediate tasks generate transformed datasets (saved to disk) and the final task produces a data product, in this case, a report with daily sales (but this could be something else, like a Machine Learning model). The following diagram, shows our daily report pipeline example:
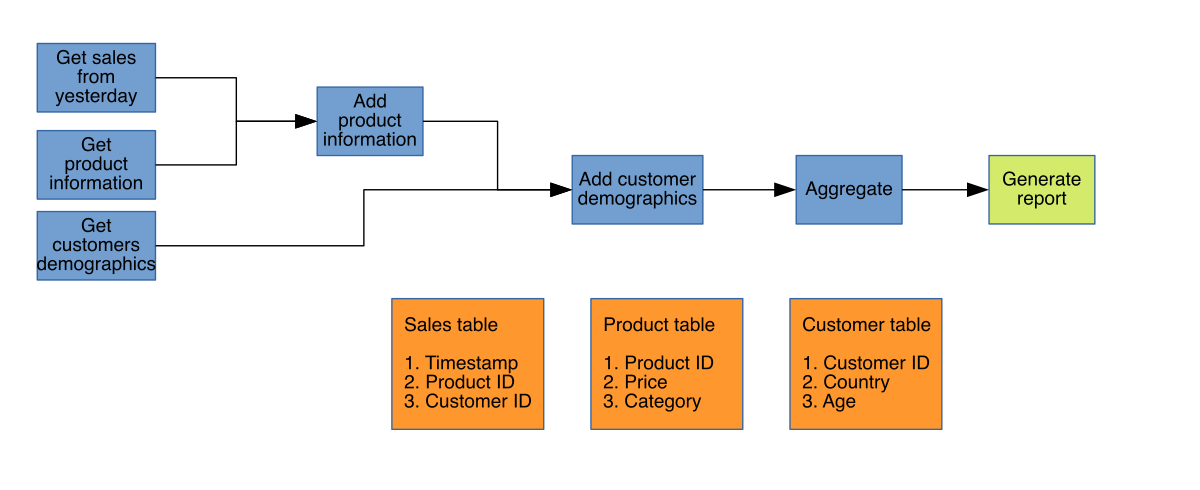
Each blue block represents a pipeline task, the green block represents a script that generates the final report. Orange blocks contain the schemas for the raw source. Every task generates one product: blue blocks generate data file (but this could also be tables/views in a database) while the green block generates the report with charts and tables.
As I mentioned in the prelude, the last task in the data pipeline is often what gets the most attention (e.g. the trained model in a Machine Learning pipeline). Not surprisingly, existing articles on CI for Data Science/Machine Learning also focus on this; but to effectively apply the CI framework we have to think in terms of the whole computational chain: from getting raw data to delivering a data product. Failing to acknowledge that a data pipeline has a richer structure causes data scientists to focus too much on the very end and ignore code quality in the rest of the tasks.
In my experience, most bugs generate along the way, even worse, in many cases errors won’t break the pipeline, but contaminate your data and compromise your results. Each step should be given equal importance.
Let’s make things more concrete with a description of the proposed workflow:
customers table have a non-empty customer_id value)Such workflow has two primary advantages:
This workflow is what software engineers do in traditional software projects. I call this ideal workflow because it is what we’d do if we could do an end-to-end pipeline run in a reasonable amount of time. This isn’t true for a lot of projects due to data scale: if our pipeline takes hours to run end-to-end it is unfeasible to run it every time we make a small change. This is why we cannot simply apply the standard CI workflow (steps 1 to 4) to Data Science. We’ll make a few changes to make it feasible for projects where running time is a challenge.
CI allows developers to continuously integrate code changes by running automated tests: if any of the tests fail, the commit is rejected. This makes sure that we always have a working project in the main branch.
Traditional software is developed in small, largely independent modules. This separation is natural, as there are clear boundaries among components (e.g. sign up, billing, notifications, etc). Going back to the e-commerce website use case, an engineer’s to-do list might look like this:
Once the engineer writes the code to support such functionality (or even before!), he/she will make sure the code works by writing some tests, which will execute the code being tested and check it behaves as expected:
from my_project import create_account, users_db
def test_create_account():
# simulate creating a new account
create_account('someone@ploomber.io', 'somepassword')
# verify the account was created by qerying the users database
user = users_db.find_with_email('someone@ploomber.io')
assert user.exists()
But unit testing is not the only type of testing, as we will see in the next section.
There are four levels of software testing. It is important to understand the differences to develop effective tests for our projects. For this post, we’ll focus on the first two.
The snippet I showed in the previous section is called a unit test. Unit tests verify that a single unit works. There isn’t a strict definition of unit but it’s often equivalent to calling a single procedure, in our case, we are testing the create_account procedure.
Unit testing is effective in traditional software projects because modules are designed to be largely independent from each other; by unit testing them separately, we can quickly pinpoint errors. Sometimes new changes break tests not due to the changes themselves but because they have side effects, if the module is independent, it gives us guarantee that we should be looking for the error within the module’s scope.
The utility of having procedures is that we can reuse them by customizing their behavior with input parameters. The input space for our create_account function is the combination of all possible email addresses and all possible passwords. There is an infinite number of combinations but it is reasonable to say that if we test our code against a representative number of cases we can conclude the procedure works (and if we find a case where it doesn’t, we fix the code and add a new test case). In practice this boils down to testing procedure against a set of representative cases and known edge cases.
Given that tests run in an automated way, we need a pass/fail criteria for each. In the software engineering jargon, this is called a test oracle. Coming up with good test oracles is essential for testing: tests are useful to the extent that they evaluate the right outcome.
The second testing level are integration tests. Unit tests are a bit simplistic since they test units independently, this simplification is useful for efficiency, as there is no need to start up the whole system to test a small part of it.
But sometimes errors arise when inputs and outputs cross module’s boundaries. Even though our modules are largely independent, they still have to interact with each other at some point (e.g. the billing module has to talk to the notifications module to send a receipt). To catch potential errors during this interaction we use integration testing.
Writing integration tests is more complex than writing unit tests as there are more elements to be considered. This is why traditional software systems are designed to be loosely coupled, by limiting the number of interactions and avoiding cross-module side effects. As we will see in the next section, integration testing is essential for testing data projects.
Writing tests is an art of its own, the purpose of testing is to catch as most errors as we can during development so they don’t show up in production. In a way, tests are simulating user’s actions and check that the system behaves as expected, for that reason, an effective test is one that simulates realistic scenarios and appropriately evaluates whether the system did the right thing or not.
An effective test should meet four requirements:
1. The simulated state of the system must be representative of the system when the user is interacting with it
The goal of tests is to prevent errors in production, so we have to represent the system status as closely as possible. Even though our e-commerce website might have dozens of modules (user signup, billing, product listing, customer support, etc), they are designed to be as independent as possible, this makes simulating our system easier. We could argue that having a dummy database is enough to simulate the system when a new user signs up, the existence or absence of any other module should have no effect in the module being tested. The more interactions among components, the harder it is to test a realistic scenario in production.
2. Input data be representative of real user input
When testing a procedure, we want to know if given an input, the procedure does what it’s supposed to do. Since we cannot run every possible input, we have to think of enough cases that represent regular operation as well as possible edge cases (e.g. what happens if a user signs up with an invalid e-mail address). To test our create_account procedure, we should pass a few regular e-mail accounts but also some invalid ones and verify that either creates the account or shows an appropriate error message.
3. Appropriate test oracle
As we mentioned in the previous section, the test oracle is our pass/fail criteria. The simpler and smaller the procedure to test, the easier is to come up with one. If we are not testing the right outcome, our test won’t be useful. Our test for create_account implies that checking the users table in the database is an appropriate way of evaluating our function.
4. Reasonable runtime
While tests run, the developer has to wait until results come back. If testing is slow, we will have to wait for a long time which might lead to developers just ignore the CI system altogether. This causes code changes to accumulate making debugging much harder (it is easier to find the error when we changed 5 lines than when we changed 100).
In the previous sections, we described the first two levels of software testing and the four properties of an effective test. This section discusses how to adapt testing techniques from traditional software development to data projects.
Unlike modules in traditional software, our pipeline tasks (blocks in our diagram) are not independent, they have a logical execution. To accurately represent the state of our system we have to respect such order. Since the input for one task depends on the output from their upstream dependencies, root cause for an error can be either in the failing task or in any upstream task. This isn’t good for us since it increases the number of potential places to search for the bug, abstracting logic in smaller procedures and unit testing them helps reduce this problem.
Say that our task add_product_information performs some data cleaning before joining sales with products:
import pandas as pd
from my_project import clean
def add_product_information(upstream):
# load
sales = pd.read_parquet(upstream['sales'])
products = pd.read_parquet(upstream['products'])
# clean
sales_clean = clean.fix_timestamps(sales)
products_clean = clean.remove_discontinued(products)
# join
output = sales_clean.merge(products_clean, on='product_id')
output.to_parquet('clean/sales_w_product_info.parquet')
We abstracted cleaning logic in two sub-procedures clean.fix_timestamps and clean.remove_discontinued, errors in any of the sub-procedures will propagate to the output and in consequence, to any downstream tasks. To prevent this, we should add a few unit tests that verify logic for each sub-procedure in isolation.
Sometimes pipeline tasks that transform data are composed of just few calls to external packages (e.g. pandas) with little custom logic. In such cases, unit testing won’t be very effective. Imagine one of the tasks in your pipeline looks like this:
# cleaning
# ...
# ...
# transform
series = df.groupby(['customer_id', 'product_category']).price.mean()
df = pd.DatFrame({'mean_price': series})
return df
Assuming you already unit tested the cleaning logic, there isn’t much to unit test about your transformations, writing unit tests for such simple procedures is not a good investment of your time. This is where integration testing comes in.
Our pipeline flows inputs and outputs until it generates the final result. This flow can break if task input expectations aren’t true (e.g. column names), moreover, each data transformation encodes certain assumptions we make about the data. Integration tests help us verify that outputs flow through the pipeline correctly.
If we wanted to test the group by transformation shown above, we could run the pipeline task and evaluate our expectations using the output data:
# since we are grouping by these two keys, they should be unique
assert df.customer_id.is_unique
assert df.product_category.is_unique
# price is always positive, mean should be as well
assert df.mean_price > 0
# check there are no NAs (this might happen if we take the mean of
# an array with NAs)
assert not df.mean_price.isna().sum()
These four assertions are quick to write and clearly encode our output expectations. Let’s now see how we can write effective integration tests in detail.
State of the system
As we mentioned in the previous section, pipeline tasks have dependencies. In order to accurately represent the system status in our tests, we have to respect execution order and run our integration tests after each task is done, let’s modify our original diagram to reflect this:
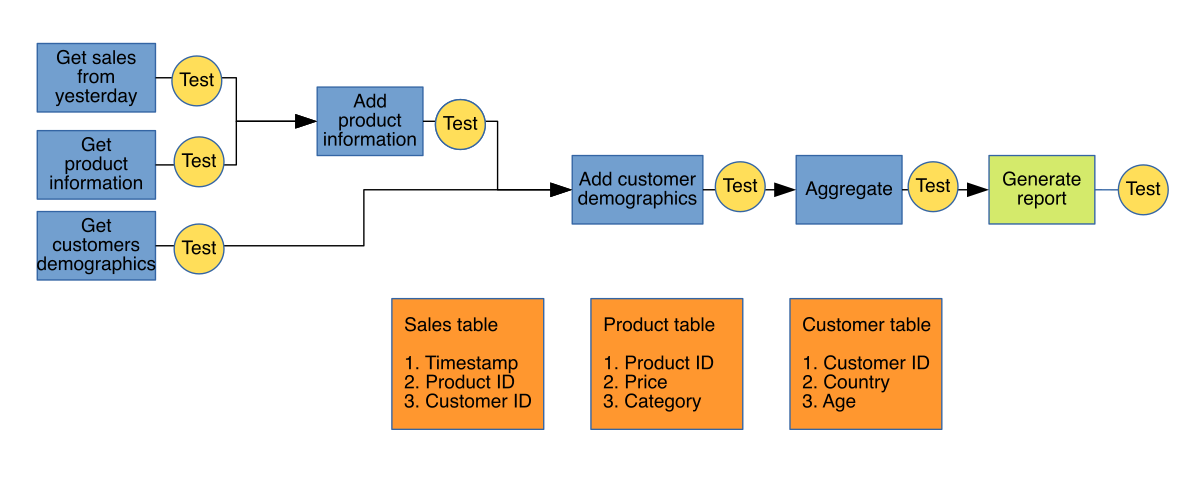
Test oracle
The challenge when testing pipeline tasks is that there is no single right answer. When developing a create_user procedure, we can argue that inspecting the database for the new user is an appropriate measure of success, but what about a procedure that cleans data?
There is no unique answer, because the concept of clean data depends on the specifics of our project. The best we can do is to explicitly code our output expectations as a series of tests. Common scenarios to avoid are including invalid observations in the analysis, null values, duplicates, unexpected column names, etc. Such expectations are good candidates for integration tests to prevent dirty data from leaking into our pipeline. Even tasks that pull raw data should be tested to detect data changes: columns get deleted, renamed, etc. Testing raw data properties help us quickly identify when our source data has changed.
Some changes such as column renaming will break our pipeline even if we don’t write a test, but explicitly testing has a big advantage: we can fix the error in the right place and avoid redundant fixes. Imagine what would happen if renaming a column breaks two downstream tasks, each one being developed by a different colleague, once they encounter the error they will be tempted to rename the column in their code (the two downstream tasks), when the correct approach is to fix in the upstream task.
Furthermore, errors that break our pipeline should be the least of our worries, the most dangerous bugs in data pipelines are sneaky; they won’t break your pipeline but will contaminate all downstream tasks in subtle ways that can severely flaw your data analysis and even flip your conclusion, which is the worst possible scenario. Because of this, I cannot stress how important is to code data expectations as part of any data analysis project.
Pipeline tasks don’t have to be Python procedures, they’ll often be SQL scripts and you should test them in the same way. For example, you can test that there are no nulls in certain column with the following query:
SELECT NOT EXISTS(
SELECT * FROM some_table
WHERE some_column IS NULL
)
For procedures whose output is not a dataset, coming up with a test oracle gets trickier. A common output in data pipelines are human-readable documents (i.e. reports). While it is technically possible to test graphical outputs such as tables or charts, this requires more setup. A first (and often good enough) approach is to unit test the input that generates visual output (e.g. test the function that prepares the data for plotting instead of the actual plot). If you’re curious about testing plots, click here.
Realistic input data and running time
We mentioned that realistic input data is important for testing. In data projects we already have real data we can use in our tests, however, passing the full dataset for testing is unfeasible as data pipelines have computationally expensive tasks that take a lot to finish.
To reduce running time and keep our input data realistic we pass a data sample. How this sample is obtained depends on the specifics of the project. The objective is to get a representative data sample whose properties are similar to the full dataset. In our example, we could take a random sample of yesterday’s sales. Then, if we want to test certain properties (e.g. that our pipeline handles NAs correctly), we could either insert some NAs in the random sample or use another sampling method such as stratified sampling. Sampling only needs to happen in tasks that pull raw data, downstream tasks will just process whatever output came from their upstream dependencies.
Sampling is only enabled during testing. Make sure your pipeline is designed to easily switch this setting off and keep generated artifacts (test vs production) clearly labeled:
from my_project import daily_sales_pipeline
def test_with_sample():
# run with sample and stores all artifacts in the testing folder
pipeline = daily_sales_pipeline(sample=True, artifacts='/path/to/output/testing')
pipeline.build()
The snippet above makes the assumption that we can represent our pipeline as a “pipeline object” and call it with parameters. This is a very powerful abstraction that makes your pipeline flexible to be executed under different settings. Upon task successful execution, you should run the corresponding integration test. For example, say we want to test our add_product_information procedure, our pipeline should call the following function once such task is done:
import pandas as pd
def test_product_information(product):
df = pd.read_parquet(product)
assert not df.customer_id.isna().sum()
assert not df.product_id.isna().sum()
assert not df.category.isna().sum()
assert not (df.price < 0).sum()
Note that we are passing the path to the data as an argument to the function, this will allow us to easily switch the path to load the data from. This is important to avoid pipeline runs to interfere with each other. For example, if you have several git branches, you can organize artifacts by branch in a folder called /data/{branch-name}; if you are sharing a server with a colleague, each one can save artifacts to /data/{username}.
If you are working with SQL scripts, you can apply the same testing pattern:
def test_product_information_sql(client, relation):
# Assume client is an object to send queries to the db
# and relation the table/view to test
query = """
SELECT EXISTS(
SELECT * FROM {product}
WHERE {column} IS NULL
)
"""
assert not client.execute(query.format(relation=relation, column='customer_id'))
assert not client.execute(query.format(relation=relation, column='product_id'))
assert not client.execute(query.format(relation=relation, column='category'))
Apart from sampling, we can we further speed up testing by running tasks in parallel. Although there’s a limited amount of parallelization we can do, which is given by the pipeline structure: we cannot run a task until their upstream dependencies are completed.
Parametrized pipelines and executing tests upon task execution is supported in our library Ploomber.
Data projects have much more uncertainty than traditional software. Sometimes we don’t know if the project is even technically possible, so we have to invest some time to give an answer. This uncertainty comes in detriment of good software practices: since we want to reduce uncertainty to estimate project’s impact, good software practices (such as testing) might not be not perceived as actual progress and get overlooked.
My recommendation is to continuously increase testing as you make progress. During early stages, it is important to focus on integration tests as they are quick to implement and very effective. The most common errors in data transformations are easy to detect using simple assertions: check that IDs are unique, no duplicates, no empty values, columns fall within expected ranges. You’ll be surprised how many bugs you catch with a few lines of code. These errors are obvious once you take a look at the data but might not even break your pipeline, they will just produce wrong results, integration testing prevents this.
Second, leverage off-the-shelf packages as much as possible, especially for highly complex data transformations or algorithms; but beware of quality and favor maintained packages even if they don’t offer state-of-the-art performance. Third-party packages come with their own tests which reduces work for you.
There might also be parts that are not as critical or are very hard to test. Plotting procedures are a common example: unless you are producing a highly customized plot, there is little benefit on testing a small plotting function that just calls matplotlib and customizes axis a little bit. Focus on testing the input that goes into the plotting function.
As your project matures, you can start focusing on increasing your testing coverage and paying some technical debt.
When tests fail, it is time to debug. Our first line of defense is logging: whenever we run our pipeline we should generate a relevant set of logging records for us to review. I recommend you to take a look to the logging module in the Python standard library which provides a flexible framework for this (do not use print for logging), a good practice is to keep a file with logs from every pipeline run.
While logging can hint you where the problem is, designing your pipeline for easy debugging is critical. Let’s recall our definition of data pipeline:
Series of ordered tasks whose inputs are raw datasets, intermediate tasks generate transformed datasets (saved to disk) and the final task produces a data product.
Keeping all intermediate results in memory is definitely faster, as disk operations are slower than memory. However, saving results to disk makes debugging much easier. If we don’t persist intermediate results to disk, debugging means we have to re-execute our pipeline again to replicate the error conditions, if we keep intermediate results, we just have to reload the upstream dependencies for the failing task. Let’s see how we can debug our add_product_information procedure using the Python debugger from the standard library:
import pdb
pdb.runcall(add_product_information,
upstream={'sales': path_to_sales, 'product': path_to_product})
Since our tasks are isolated from each other and only interact via inputs and outputs, we can easily replicate the error conditions. Just make sure that you are passing the right input parameters to your function. You can easily apply this workflow if you use Ploomber’s debugging capabilities.
Debugging SQL scripts is harder since we don’t have debuggers as we do in Python. My recommendation is to keep your SQL scripts in a reasonable size: once a SQL script becomes too big, you should consider breaking it down in two separate tasks. Organizing your SQL code using WITH helps with readability and can help you debug complex statements:
WITH customers_subset AS (
SELECT * FROM customers WHERE ..
), products_subset AS (
SELECT * FROM products WHERE ...
),
SELECT *
FROM customers
JOIN products
USING (product_id)
If you find an error in a SQL script organized like this, you can replace the last SELECT statement for something like SELECT * FROM customers_subset to take a look at intermediate results.
In traditional software, tests are only run in the development environment, it is assumed that if a piece of code reaches production, it must have been tested and works correctly.
For data pipelines, integration tests are part of the pipeline itself and it is up to you to decide whether to execute them or not. The two variables that play here are response time and end-users. If running frequency is low (e.g. a pipeline that executes daily) and end-users are internal (e.g. business analysts) you should consider keeping the tests in production. A Machine Learning training pipeline also follows this pattern, it has low running frequency because it executes on demand (whenever you want to train a model) and the end-users are you and any other person in the team. This is important given that we originally ran our tests with a sample of the data, running them with the full dataset might give a different result if our sampling method didn’t capture certain properties in the data.
Another common (and often unforeseeable) scenario are data changes. It is important that you keep yourself informed of planned changes in upstream data (e.g. a migration to a different warehouse platform) but there’s still a chance that you’d find out data changes until you pass new data through the pipeline. In the best case scenario, your pipeline will raise an exception that you’ll be able to detect, worst case, your pipeline will execute just fine but the output will contain wrong results. For this reason, it is important to keep your integration tests running in the production environment.
Bottom line: If you can allow a pipeline to delay its final output (e.g the daily sales report), keep tests in production and make sure you are properly notified about them, the simplest solution is to make your pipeline send you an e-mail.
For pipelines where output is expected often and quickly (e.g. an API) you can change your strategy. For non-critical errors, you can log instead of raising exceptions but for critical cases, where you know a failing test will prevent you from returning an appropriate results (e.g. user entered a negative value for an “age” column), you should return an informative error message. Handling errors in production is part of model monitoring, which we will cover in an upcoming post.
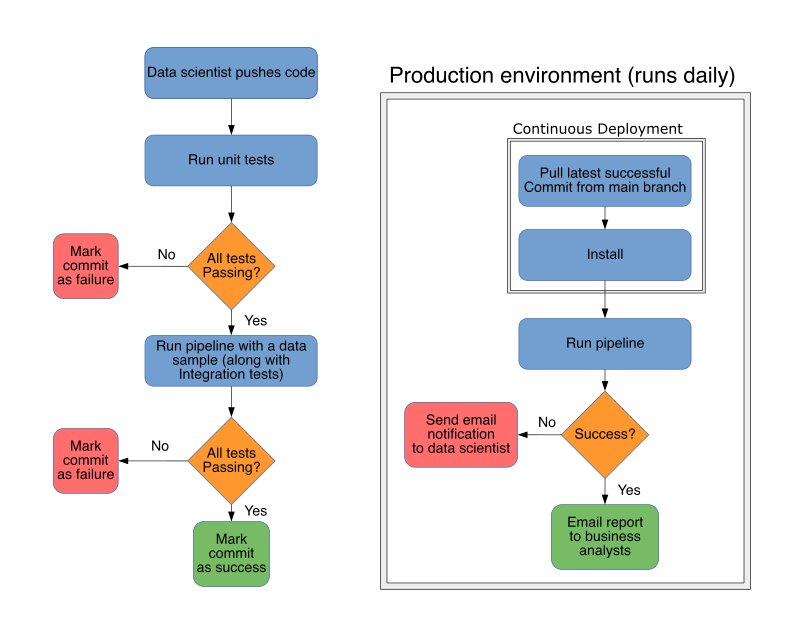
We now revisit the workflow based on observations from the previous sections. On every push, unit tests run first, the pipeline is then executed with a sample of the data, upon each task execution, integration tests run to verify each output, if all tests pass, the commit is marked as successful. This is the end of the CI process and should only take a few minutes.
Given that we are continuously testing each code change, we should be able to deploy anytime. This idea of continuously deploying software is called Continuous Deployment, it deserves a dedicated post but here’s the summary.
Since we need to generate a daily report, the pipeline runs every morning. The first step is to pull (from the repository or an artifact store) the latest stable version available and install it in the production server, integration tests run on each successful task to check data expectations, if any of these tests fails, a notification is sent. If everything goes well, the pipeline emails the report to business analysts.
This section provides general guidelines and resources to implement the CI workflow with existing tools.
Unit testing
To unit test logic inside each data pipeline task, we can leverage existing tools. I highly recommend using pytest. It has a small learning curve for basic usage; as you get more comfortable with it, I’d recommend you to explore more of its features (e.g. fixtures). Becoming a power user of any testing framework comes with great benefits, as you’ll invest less time writing tests and maximize their effectiveness to catch bugs. Keep practicing until writing tests becomes the natural first step before writing any actual code. This technique of writing tests first is called Test-driven development (TDD).
Running integration tests
Integration tests have more tooling requirements since they need to take the data pipeline structure into account (run tasks in order), parametrization (for sampling) and testing execution (run tests after each task). There’s been a recent surge in workflow management tools that can be helpful to do this to some extent.
Our library Ploomber supports all features required to implement this workflow: representing your pipeline as a DAG, separating dev/test/production environments, parametrizing pipelines, running test functions upon task execution, integration with the Python debugger, among other features.
External systems
A lot of simple to moderately complex data applications are developed in a single server: the first pipeline tasks dump raw data from a warehouse and all downstream tasks output intermediate results as local files (e.g. parquet or csv files). This architecture allows to easily contain and execute the pipeline in a different system: to test locally, just run the pipeline and save the artifacts in a folder of your choice, to run it in the CI server, just copy the source code and execute the pipeline there, there is no dependency on any external system.
However, for cases where data scale is a challenge, the pipeline might just serve as an execution coordinator doing little to no actual computations, think for example of a purely SQL pipeline that only sends SQL scripts to an analytical database and waits for completion.
When execution depends on external systems, implementing CI is harder, because you depend on another system to execute your pipeline. In traditional software projects, this is solved by creating mocks, which mimic the behavior of another object. Think about the e-commerce website: the production database is a large server that supports all users. During development and testing, there is no need for such big system, a smaller one with some data (maybe a sample of real data or even fake data) is enough, as long as it accurately mimics behavior of the production database.
This is often not possible in data projects. If we are using a big external server to speed up computations, we most likely only have that system (e.g a company-wide Hadoop cluster) and mocking it is unfeasible. One way to tackle this is to store pipeline artifacts in different “environments”. For example, if you are using a large analytical database for your project, store production artifacts in a prod schema and testing artifacts in a test schema. If you cannot create schemas, you can also prefix all your tables and views (e.g. prod_customers and test_customers). Parametrizing your pipeline can help you easily switch schemas/suffixes.
CI server
To automate testing execution you need a CI server. Whenever you push to the repository, the CI server will run tests against the new commit. There are many options available, verify if the company you work for already has a CI service. If there isn’t one, you won’t get the automated process but you can still implement it halfway by running your tests locally on each commit.
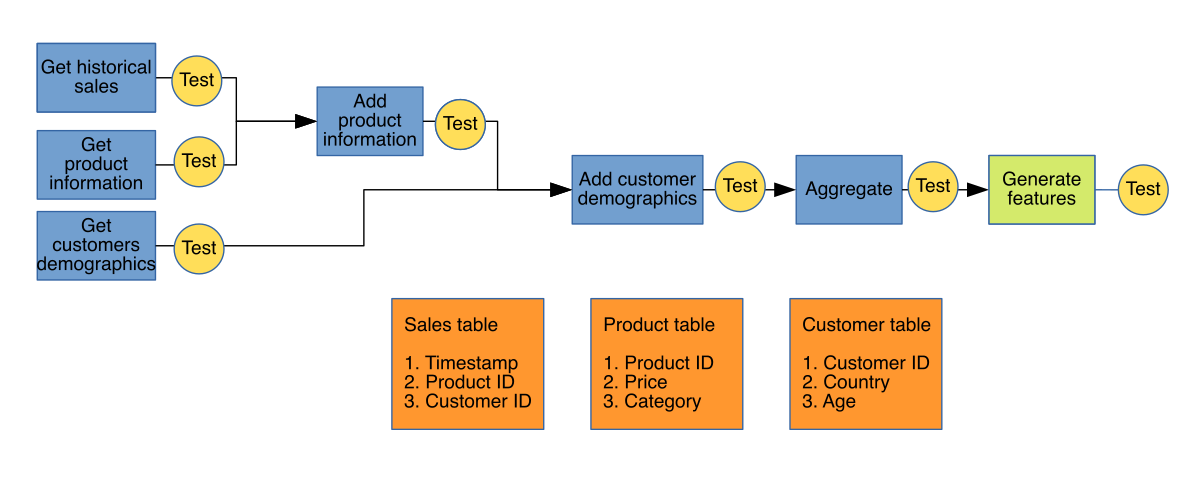
Let’s modify our previous daily report pipeline to cover an important use case: developing a Machine Learning model. Say that we now want to forecast daily sales for the next month. We could do this by getting historical sales (instead of just yesterday’s sales), generating features and training a model.
Our end-to-end process has two stages: first, we process the data to generate a training set, then we train models and select the best one. If we follow the same rigorous testing approach for each task along the way, we will be able to catch dirty data from getting into our model, remember: garbage in, garbage out. Sometimes practitioners focus too much on the training task by trying out a lot of fancy models or complex hyperparameter tuning schemas. While this approach is certainly valuable, there is usually a lot of low-hanging fruit in the data preparation process that can impact our model’s performance significantly. But to maximize this impact, we must ensure that the data preparation stage is reliable and reproducible.
Bugs in data preparation cause either results that are too good to be true (i.e. data leakage) or sub-optimal models; our tests should address both scenarios. To prevent data leakage, we can test for existence of problematic columns in the training set (e.g. a column whose value is known only after our target variable is visible). To avoid sub-optimal performance, integrations tests that verify our data assumptions play an important role but we can include other tests to check quality in our final dataset such as verifying we have data across all years and that data regarded as unsuitable for training does not appear.
Getting historical data will increase CI running time overall but data sampling (as we did in the daily report pipeline) helps. Even better, you can cache a local copy with the data sample to avoid fetching the sample every time you run your tests.
To ensure full model reproducibility, we should only train models using artifacts that generated from an automated process. Once tests pass, a process could automatically trigger an end-to-end pipeline execution with the full dataset to generate training data.
Keeping historical artifacts can also help with model audibility, given a hash commit, we should be able to locate the generated training data, moreover, re-executing the pipeline from the same commit should yield identical results.
Our current CI workflow tests our pipeline with a data sample to make sure the final output is suitable for training. Wouldn’t it be nice if we could also test the training procedure?
Recall that the purpose of CI is to allow developers integrate small changes iteratively, for this to be effective, feedback needs to come back quickly. Training ML models usually comes with a long running time; unless we have a way of finishing our training procedure in a few minutes, we’ll have to think how to test swiftly.
Let’s analyze two subtly different scenarios to understand how we can integrate them in the CI workflow.
Testing a training algorithm
If you are implementing your own training algorithm, you should test your implementation independent of the rest of your pipeline. These tests verify the correctness of your implementation.
This is something that any ML framework does (scikit-learn, keras, etc.), since they have to ensure that improvements to the current implementations do not break them. In most cases, unless you are working with a very data-hungry algorithm, this won’t come with a running time problem because you can unit test your implementation with a synthetic/toy dataset. This same logic applies to any training preprocessors (such as data scaling).
Testing your training pipeline
In practice, training is not a single-stage procedure. The first step is to load your data, then you might do some final cleaning such as removing IDs or hot-encoding categorical features. After that, you pass the data to a multi-stage training pipeline that involves splitting, data preprocessing (e.g. standardize, PCA, etc), hyperparameter tuning and model selection. Things can go wrong in any of these steps, especially if your pipeline has highly customized procedures.
Testing your training pipeline is hard because there is no obvious test oracle. My advice is to try to make your pipeline as simple as possible by leveraging existing implementations (scikit-learn has amazing tools for this) to reduce the amount of code to test.
In practice, I’ve found useful to define a test criteria relative to previous results. If the first time I trained a model I got an accuracy of X, then I save this number and use it as reference. Subsequent experiments should fall within a reasonable range of X: sudden drops or gains in performance trigger an alert to review results manually. Sometimes this is good news, it means that performance is improving because new features are working, other times, it is bad news: sudden gains in performance might come from information leakage while sudden drops from incorrectly processing data or accidentally dropping rows/columns.
To keep running time feasible, run the training pipeline with the data sample and have your test compare performance with a metric obtained using the same sampling procedure. This is more complex than it sounds because results variance will increase if you train with less data which makes coming up with the reasonable range more challenging.
If the above strategy does not work, you can try using a surrogate model in your CI pipeline that is faster to train and increase your data sample size. For example, if you are training a neural network, you could train using a simpler architecture to make training faster and increase the data sample used in CI to reduce variance across CI runs.
CI allows us to integrate code in short cycles, but that’s not the end of the story. At some point we have to deploy our project, this is where Continuous Delivery and Continuous Deployment come in.
The first step towards deployment is releasing our project. Releasing is taking all necessary files (i.e. source code, configuration files, etc) and putting them in a format that can be used for installing our project in the production environment. For example, releasing a Python package requires uploading our code to the Python Package Index.
Continuous Delivery ensures that software can be released anytime, but deployment is still a manual process (i.e. someone has to execute instructions in the production environment), in other words, it only automates the release process. Continuous Deployment involves automating release and deployment. Let’s now analyze this concepts in terms of data projects.
For pipelines that produce human-readable documents (e.g. a report), Continuous Deployment is straightforward. After CI passes, another process should grab all necessary files and create a an installable artifact, then, the production environment can use this artifact to setup and install our project. Next time the pipeline runs, it should be using the latest stable version.
On the other hand, Continuous Deployment for ML pipelines is much harder. The output of a pipeline is not a unique model, but several candidate models that should be compared to deploy the best one. Things get even more complicated if we already have a model in production, because it could be that no deployment is the best option (e.g. if the new model doesn’t improve predictive power significantly and comes with an increase in runtime or more data dependencies).
An even more important (and more difficult) property to assess than predictive power is model fairness. Every new deployment must be evaluated for bias towards sensitive groups. Coming up with an automated way to evaluate a model in both predictive power and fairness is difficult and risky. If you want to know more about model fairness, this is a great place to start.
But Continuous Delivery for ML is still a manageable process. Once a commit passes all tests with a data sample (CI), another process runs the pipeline with the full dataset and stores the final dataset in object storage (CD stage 1).
The training procedure then loads the artifacts and finds optimal models by tuning hyperparameters for each selected algorithms. Finally, it serializes the best model specification (i.e. algorithm and its best hyperparameters) along with evaluation reports (CD stage 2). When it’s all done, we take a look at the reports and choose a model for deployment.
In the previous section, we discussed how we can include model evaluation in the CI workflow. The proposed solution is limited by CI running time requirements; after the first stage in the CD process is done, we can include a more robust solution by training the latest best model specification with the full dataset, this will catch bugs causing performance drops at the moment, instead of having to wait for the second stage to finish, given it has a much higher running time. The CD workflow looks like this:
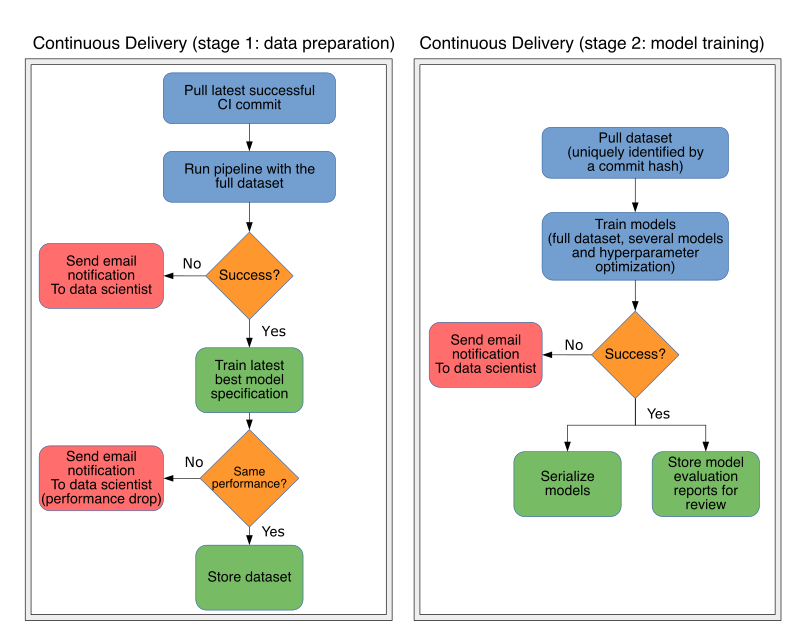
Triggering CD from a successful CI run can be manual, a data scientist might not want to generate datasets for every passing commit, but it should be easy to do so given the commit hash (i.e. with a single click or command).
It is also convenient allow manual execution of the second stage because data scientists often use the same dataset to run several experiments by customizing the training pipeline, thus, a single dataset can potentially trigger many training jobs.
Experiment reproducibility is critical in ML pipelines. There is a one-to-one relationship between a commit, a CI run and a data preparation run (CD stage 1), thus, we can uniquely identify a dataset by the commit hash that generated it. And we should be able to reproduce any experiment by running the data preparation step again and running the training stage with the same training parameters.
As CI/CD processes for Data Science start to mature and standardize, we’ll start to see new tools to ease implementation. Currently, a lot of data scientists are not even considering CI/CD as part of their workflow. In some cases, they just don’t know about it, in others, because implementing CI/CD effectively requires a complicated setup process for re-purposing existing tools. Data scientists should not worry about setting up a CI/CD service, they should just focus on writing their code, tests and push.
Apart from CI/CD tools specifically tailored for data projects, we also need data pipeline management tools to standardize pipeline development. In the last couple years, I’ve seen a lot of new projects, unfortunately, most of them focus on aspects such as scheduling or scaling rather than user experience, which is critical if we want software engineering practices such as modularization and testing to be embraced by all data scientists. This is the reason why we built Ploomber, to help data scientists easily and incrementally adopt better development practices.
Shortening the CI-developer feedback loop is critical for CI success. While data sampling is an effective approach, we can do better by using incremental runs: changing a single task in a pipeline should only trigger the least amount of work by re-using previously computed artifacts. Ploomber already offers this with some limitations and we are experimenting ways to improve this feature.
I believe CI is the most important missing piece in the Data Science software stack: we already have great tools to perform AutoML, one-click model deployment and model monitoring. CI will close the gap to allow teams confidently and continuously train and deploy models.
To move our field forward, we must start paying more attention to our development processes.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

