


When helping members of our community with architectural decisions regarding their data pipelines, a recurring question is how to group the analysis logic into tasks. This blog post summarizes the advice we’ve given to our community members for writing clean data pipelines. Our objective is to prevent an anti-pattern we’ve seen, where pipelines contain gigantic tasks:
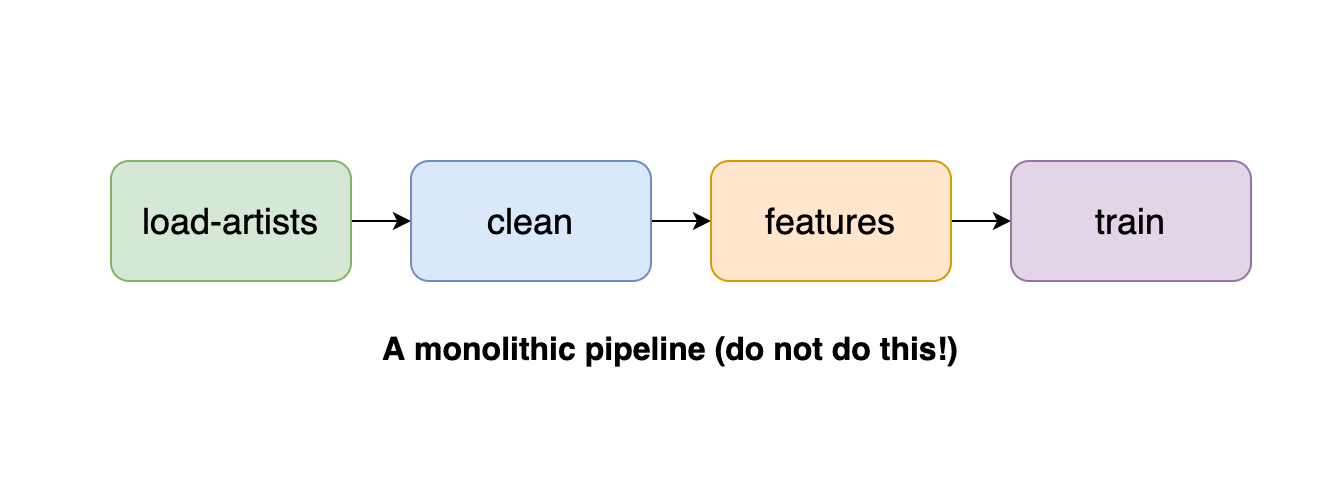
These monolithic pipelines have many problems: they make collaboration harder because plenty of logic concentrates on the same task. Secondly, you need to navigate through the source code to find what you need. Monolithic pipelines are also harder to test since there aren’t any clear expectations on the output of each task. Finally, they’re computationally inefficient since they do not fully utilize parallelization. A common reason we’ve encountered when practitioners build this kind of pipeline is that the framework they’re using is so complex that adding a new task requires a lot of effort, so they minimize the number of tasks to get things done. If you are encountering this problem, switch to another framework that allows you to create granular tasks quickly (Ploomber is an excellent choice).
Before diving into the details, let’s get on the same page and clearly define the concept of data pipeline.
A data pipeline represents the computations applied to one or more datasets, where the output of a given task becomes the input of the next one. Here’s an example of the simplest possible pipeline:
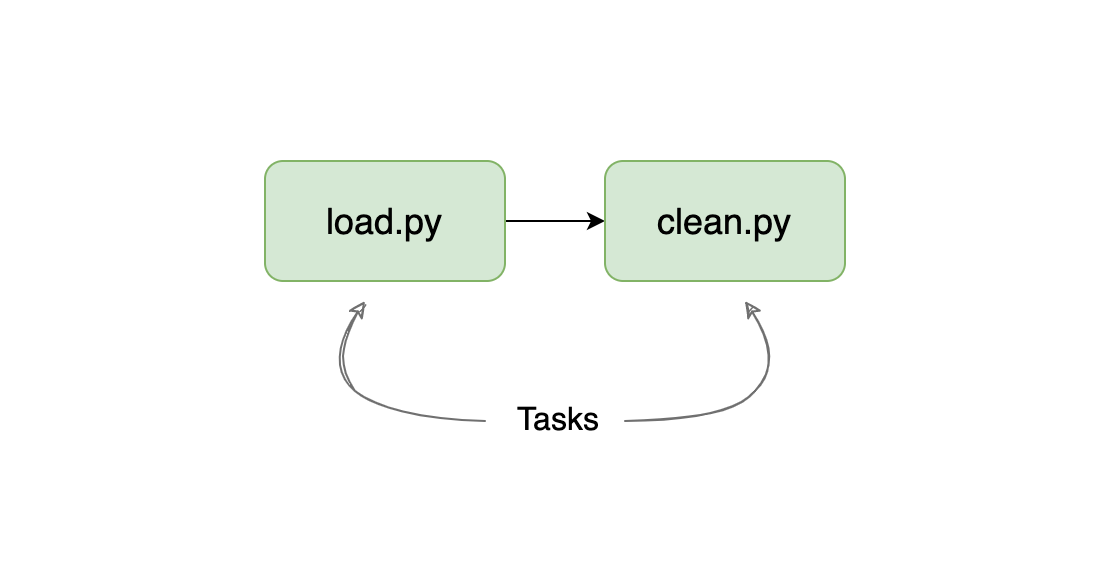
Our example pipeline loads some data and then cleans it. Note that pipelines are also called workflows.
A task is the smallest component in a pipeline. Depending on the framework you use, tasks can take many forms. For example, in Luigi, each one is a method in a class. In Airflow, it is an instance of an Operator. Finally, in Ploomber, a task can be a function, a (Python, R, SQL) script, or a notebook. The arrow represents how the data moves from one task to the other. But bear in mind that the mechanism is different from one framework to another. In some cases, this can be through files or via memory.
The pipeline and task concepts are simple, but it might be hard to decide what constitutes a task when applying the idea to a real-world problem. Here are our three recommendations:
These three simple rules will allow you to build more robust and maintainable pipelines; let’s do a quick example to illustrate our point. Let’s say you’re working with music data. You may have an artists table, a songs table, and a genres table. Following the recommendations, we end up with a pipeline like this:
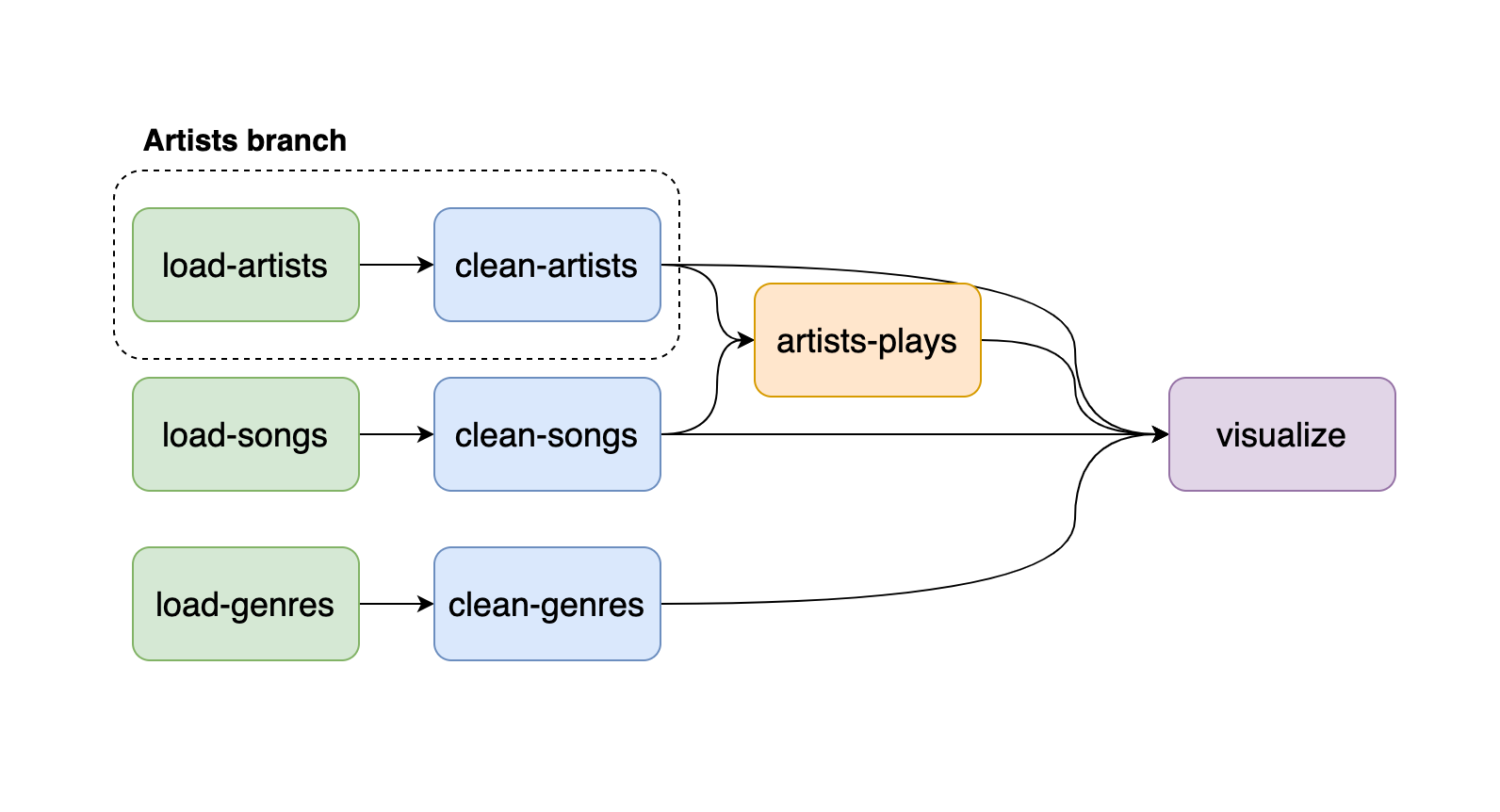
Each table contains a load-* and a clean-* task, and each part constitutes a pipeline branch. Note that by branch, we mean a set of tasks in your pipeline (e.g., load-artists and clean-artists are a branch), not to confuse with a git branch. Once we finish cleaning our data, we may realize we need to aggregate songs at the artist level to get play statistics. Hence, we create the artist-plays task. Finally, we visualize our data in the visualize task.
Following the rules listed above allows us to define a clear responsibility for each task. For example, we know that a load-* task is to load data and nothing more. A clean-* cleans a given dataset, and that artist-plays aggregates artists and songs. Furthermore, suppose we find out that a given dataset is unnecessary for our analysis. We can quickly prune our pipeline since we only need to delete the branch corresponding to such dataset.
Organizing pipelines this way simplifies collaboration; for example, if our colleagues want to explore the artists data, they’ll know that the best way to start is the clean-artists task since it produces clean artists data. Furthermore, if anyone wants to contribute to the data cleaning part, they’ll know what task to modify depending on the dataset they wish to clean. These clear definitions of each task’s responsibility reduce duplicated work: ambiguous definitions lead to duplicated logic scattered across tasks.
Finally, whenever we want to aggregate two or more datasets, it’s essential to create a new task whose only purpose is to make this new aggregated dataset. Essentially, this new task is creating a derived dataset; since we’re being explicit about it, other people can use it to build on top of it. For example, we could’ve made the visualize task include the data aggregation logic, but this would’ve made it impossible for people to know that we already have logic aggregating songs at the artist level.
If you’re working on a Machine Learning pipeline, we have a couple more recommendations:
When writing features for a Machine Learning model, we can usually group them. This grouping is subjective, but it helps us organize the pipeline. The easiest way to group features is by their input data. For example, if you’re using the clean-artists dataset as input, you can create one task that generates features and calls it features-artists. However, in cases where you can generate many features from the same input data, you may want to group them more granularly. For example, sometimes, you may have features that use the same input data. Still, each feature column might be computed using a different transformation (for example, a threshold or an affine transformation). If you can group features depending on a high-level definition of a transformation, you can define a feature group.
For example, you may want to aggregate songs data at the artist level, then generate features based on a count aggregation: how many songs the artist has, how many songs over 5 minutes, how many songs were released before 2020, etc. Here, count is the transformation so that we can create a feature group with all count features. In addition, we recommend prefixing all columns in the feature group; this will allow you to easily select (or unselect) the group entirely based on the prefix when training the model.
After the feature tasks, create another task to consolidate all features to generate the training set; then, parallel training tasks use this as input. For finding the best model, you may want to train many of them, so you may define training task as one that trains a specific model type (e.g., XGBoost) and repeat the same logic for other models (e.g., Random Forest). Note: If want to optimize parameters and do model selection, use nested cross-validation.
Finally, for each training task, add an evaluation task, and use this evaluation task to generate metrics and plots to help you understand each model in detail. Finally, you may add a final task that takes all the candidate models and picks up the best one. If you follow these recommendations, your pipeline will look like this:
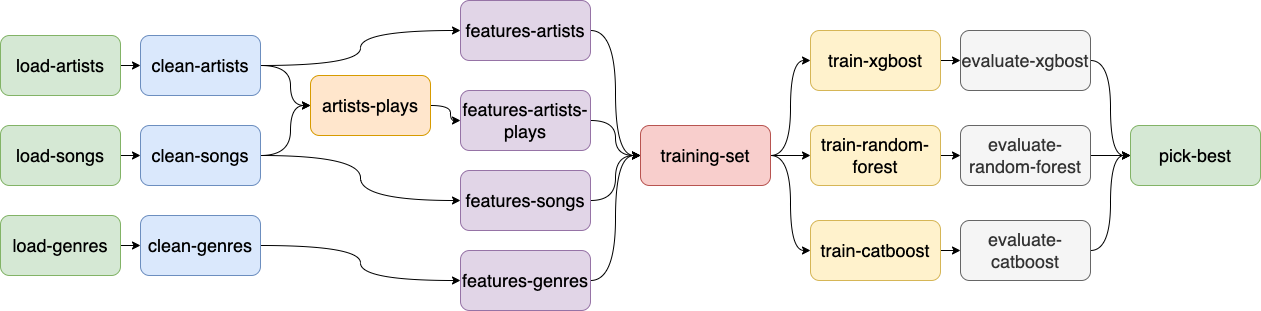
Tip: a great way to keep your training and evaluation stage simple is to create task templates. For example, you may have a tasks.py that takes the model type as an input parameter and re-use the same file to create the train-xgboost, train-random-forest, train-catbost tasks by simply passing a different parameter to the task.py file. Here’s an example of how to achieve that with Ploomber. Finally, you could re-use the same evaluate.py script if you make each train-* task return their outputs in the same format (example: a model.pkl file and a dataset with cross-validated predictions).
In practice, following these rules requires discipline. For example, say you’re working on adding features at the artist level (i.e. the features-artists task). You may encounter that the data isn’t as clean as you expected, so you’ll be tempted to add a few extra cleaning code in the feature-artists task; do not do this. Instead, go to the corresponding cleaning task (clean-artists), add the new cleaning code there, then keep working on the features code in feature artists. Keeping the cleaning logic in a single place has another advantage: all downstream tasks will benefit from the new cleaning code. In our case, both feature-artists and artist-plays depend on clean-artists, so we ensure that all consumers benefit from the cleanest version by concentrating the cleaning logic on clean-artists.
Abiding by the rules makes maintainability easier since extending the pipeline becomes a no-brainer. Do you want to compute genre features at the artist level? Grab clean-artist and clean-genres? Did you find an issue in the songs dataset? Open a pull request to modify the clean-songs task.
If you think your use case does not fit into these definitions, ping us, and we’ll happily help you design a clean data pipeline.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

