



This short article is relevant to you if …
Microsoft Excel, or it’s no longer the right tool for you.Python based toolsA special thanks to Ido Michael (@idomic) for reviewing/editing this article!
The architecture we’ve used:
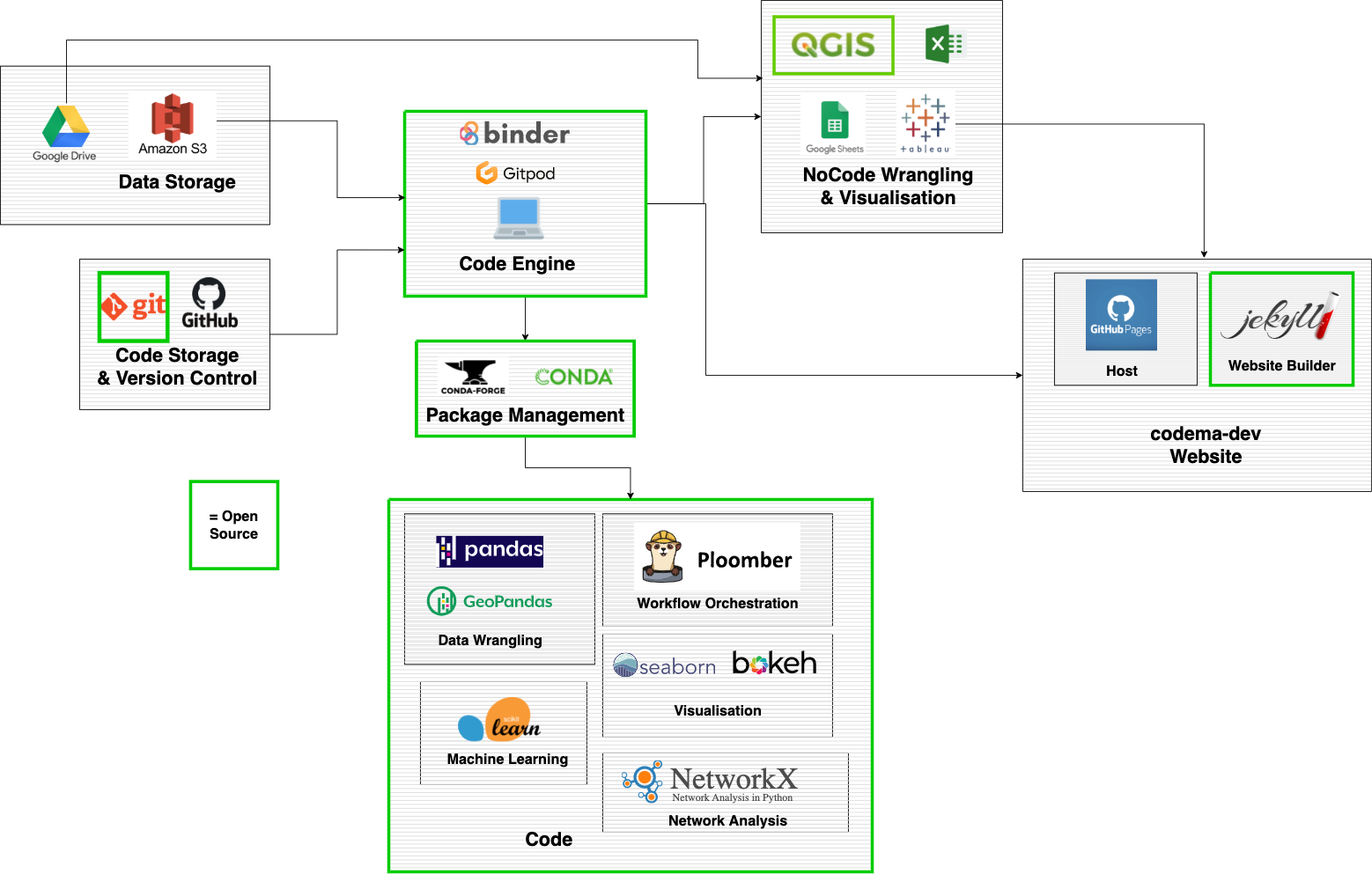
My team & I wanted to model the Dublin energy system for the purposes of energy planning. Previously, we solely relied on Microsoft Excel to solve our problems. It’s a powerful tool and fast to learn, however, it can be limiting when it’s used for the wrong job. Large datasets can cause crashes when operating locally. In addition, sharing analytics when the underlying data is closed-access is almost impossible because data and logic (cleaning, transformations, merging data etc) tend to be tightly coupled. This coupling makes it difficult to collaborate with others within the team, to reproduce the data, reuse it or improve your team analytics overall. We’ll see how Ploomber among other tools helped us solving this problem.
Python enables decoupling the data and logic, but the tradeoff is that the switch is not intuitive. Skillset will be the first gap to deal with - you need to learn the basics of Python and the pandas “extension” (dependency) for spreadsheet operations. Next, you’ll need some tool/compute resources to run your scripts (like Jupyter Notebook). If you have trouble installing everything, you may have no choice but to use the command line. Overall, setting up the environment should be straightforward and well documented. If you want to share your work (which you should if the team size is > 2), you’ll also need to specify the versions of your dependencies using a configuration file to avoid version mismatches. This is a lot to ask.
Once you start using Jupyter Notebook the temptation is to write all of your logic in a single monolith notebook. Over time as this notebook grows and becomes more difficult to maintain, run and share. Some of those notebooks may even get into situations where they can’t be executed by others since the execution order isn’t linear. Splitting notebooks into smaller components (scripts or notebooks) speed up runtimes, simplifies maintenance, and enables better code reusability. Now you have a new challenge, how to run them?
We used Ploomber since it was very easy to get started, it uses a simple configuration file (yaml) to specify file run-order. You can now read, edit & run flows without reading any code. As an added bonus, Ploomber enables rendering flow steps as notebooks that can run independently of the flow. In addition, Ploomber helped us break our notebook into a modular pipeline, which enabled incremental runs and faster iterations thus avoiding expensive and slow data loads. Now another problem, how to share this work with colleagues without requiring them to install anything?
We used GitHub as our version control tool for storing & versioning code, Amazon s3 for data storage (which Ploomber integrated seamlessly and simplified our lives), and binder.org to create a sandbox environment that anyone can run in their browser. GitHub uses Git to version code, which if used directly can be hard to get your head around. Graphics User Interfaces (GUI) like Git Graph for Vscode or Github Desktop help. Amazon s3 enables sharing data via URLs, or if it’s closed-access, programmatically via credentials.
Do you need more computing power? We got you covered; you can export your pipelines and execute them in Kubernetes, Airflow, AWS Batch, and SLURM without code changes. Check out our documentation for details.
If you think the cost of upskilling is worth the benefits, checkout the GitHub repository to view, run or copy any of our projects:
https://github.com/codema-dev/projects
Join our community, and we’ll be happy to answer all your questions.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

