



In containerized application development, creating efficient and accurate Dockerfiles is essential for deployment consistency and scalability. As Large Language Models (LLMs) advance, their potential for automating Dockerfile generation becomes an interesting area of study.
During the development of an AI-assisted debugging tool for pipelines, we encountered varying results when using different LLMs to generate Dockerfiles. This prompted a more systematic investigation into their performance, with a particular focus on comparing more resource-intensive models against lighter alternatives like GPT-4o-mini.
Question: Which LLM is best for generating Dockerfiles, and which should you choose, the biggest and smartest or the most cost-effective?
This analysis examines our methodology, findings from investigating this question, and the practical implications for developers and DevOps professionals. We aim to provide an objective assessment of how various LLMs perform in Dockerfile generation tasks, considering factors such as accuracy, efficiency, and resource requirements.
Dockerfiles are the blueprint for containerized applications, defining the environment, dependencies, and configuration needed to run your code consistently across different systems. Getting these right is critical for several reasons:
Consistency: Ensures your application behaves the same way in development, testing, and production environments.
Efficiency: Well-crafted Dockerfiles lead to optimized container images, reducing build times and resource usage.
Scalability: Properly containerized applications can be easily scaled horizontally to meet demand.
Portability: Containers can run on any system that supports Docker, simplifying deployment across different infrastructures.
However, creating optimal Dockerfiles can be challenging, especially for complex applications or those unfamiliar with containerization best practices. This is where AI-assisted generation could potentially streamline the process.
To evaluate the effectiveness of different LLMs in generating Dockerfiles, we developed a systematic approach:
We chose 10 diverse projects representing various complexities and tech stacks, from simple web applications to complex ML pipelines.
We created docker-generate, a tool that provides a consistent interface between project structures and AI models.
The tool extracts relevant information from project files (e.g., requirements.txt, README.md) to provide context to the LLMs.
We tested three models: GPT-4o, GPT-4o-mini, and Claude 3.5 Sonnet.
For failed attempts, we provided error messages back to the LLMs and allowed a retry.
We selected and created 10 diverse projects representing various project types and complexities:
| ID | Project & Description | Framework | Dockerfile Complexity |
|---|---|---|---|
| 1 | Ploomber AI Debugger | Streamlit | Easy: Port exposure, env variables |
| 2 | Streamlit with a Database | psycopg2 | Easy: Requires gcc for package building |
| 3 | JAN: LLM local inference | LLM framework | High: GPU config, full dev environment |
| 4 | Recommendation System | Streamlit + Surprise | Medium: gcc for package building |
| 5 | Simple React Webapp | React | Low: Basic Node.js setup |
| 6 | Gaussian Blur Image Processor | Dash + OpenCV | Medium: OpenCV dependencies |
| 7 | Image Classifier: CPU vs GPU inference | Streamlit + PyTorch | High: CUDA access configuration |
| 8 | Microservices: Web server, queue, worker | Flask + Redis + Celery | Medium: Multiple Dockerfiles needed with a missing python package |
| 9 | ETL Data Pipeline | Airflow + PostgreSQL | High: System deps, DB setup, Airflow config |
| 10 | ML Model Serving via API | FastAPI + MLflow | High: Model versioning, environment reproduction |
Each LLM generates Dockerfiles based on minimal project information. For complex scenarios (e.g., GPU access, multi-container setups), additional context is provided to ensure fair comparison.
init.sql and Dockerfile for the database is in a db_setup/ folder (not given to LLM).docker-compose.yml is provided but Werkzeug is missing from dependencies.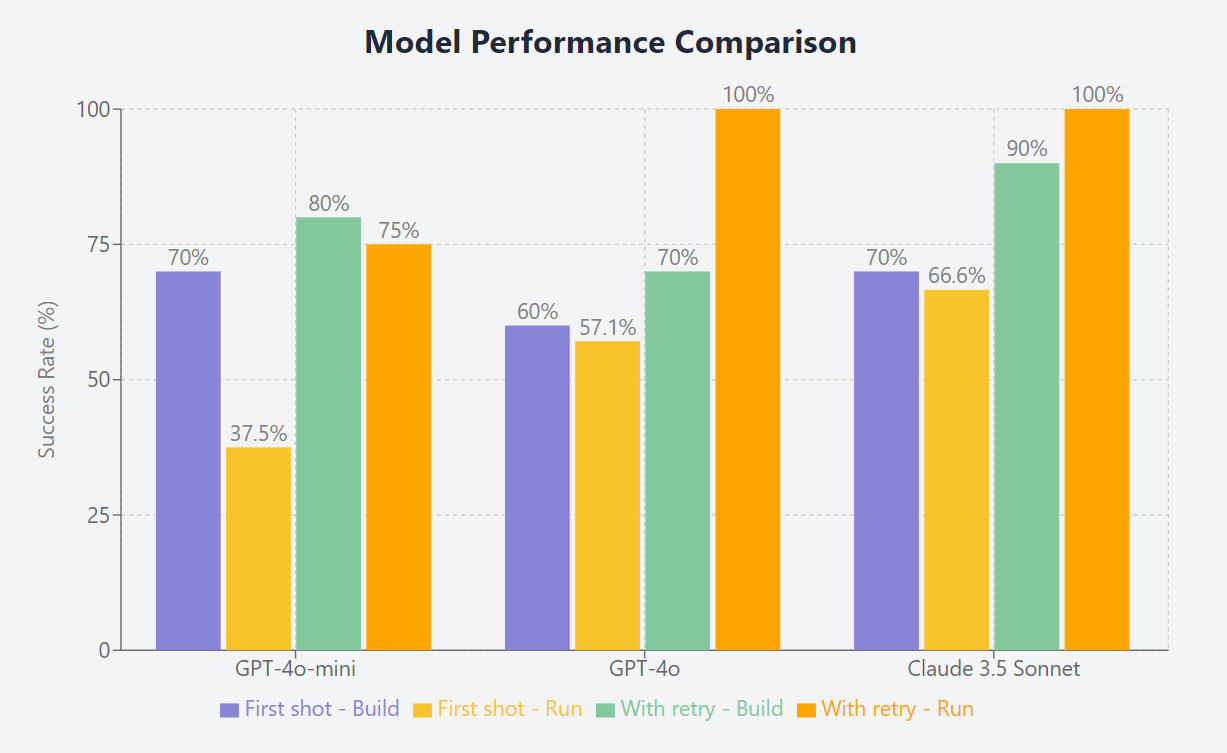
| Model | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Build Success Rate |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o-mini | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | 70% |
| GPT-4o-mini with retry | ✅ | ❌ | ❌ | 80% | |||||||
| GPT-4o | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ | 60% |
| GPT-4o with retry | ❌ | ✅ | ❌ | ❌ | 70% | ||||||
| Sonnet | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | 70% |
| Sonnet with retry | ❌ | ✅ | ✅ | 90% |
| Model | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Run Success Rate |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o-mini | ❌ | ❌ | ❌ | - | ✅ | ✅ | ✅ | ❌ | - | ❌ | 37.5% |
| GPT-4o-mini with retry | ✅ | ✅ | ❌ | ❌ | ✅ | 75% | |||||
| GPT-4o | ❌ | ✅ | - | ✅ | ✅ | ✅ | - | ❌ | - | ❌ | 57.1% |
| GPT-4o with retry | ✅ | ✅ | ✅ | 100% | |||||||
| Sonnet | ❌ | ✅ | - | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | 66.6% |
| Sonnet with retry | ✅ | ✅ | ✅ | 100% |
AI-assisted Dockerfile generation shows promise in streamlining the containerization process, especially for developers new to Docker or working on complex projects. However, it’s not a silver bullet. The technology works best when combined with human oversight and domain expertise.
As LLMs continue to evolve and be trained on more up-to-date information, we can expect their performance in specialized tasks like Dockerfile generation to improve. For now, they serve as a valuable tool in the developer’s toolkit, capable of providing a solid starting point and assisting with troubleshooting.
If you’re interested in experimenting with AI-generated Dockerfiles, try it now dockerfile.ploomber.app!
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.
