


In this tutorial, we’ll show you how to build a complete Flask application that allows loading documents from Google Drive into a database, perform vector similarity search, and answer questions about the documents using OpenAI. By the end of this tutorial you’ll have a fully deployed application.
To follow this tutorial, you’ll need a Ploomber Cloud account, a Google Cloud account, and an OpenAI account.
Let’s get into it!
First, let’s install the ploomber-cloud CLI:
pip install ploomber-cloud
Download the sample code:
ploomber-cloud examples flask/gdrive-llm
cd gdrive-llm
And let’s initialize our project:
ploomber-cloud init
The init command will print our App ID, we’ll need this to configure our application
on the Google Cloud console, so save it somewhere. For example, my init command
printed:
Your app 'tight-limit-8371' has been configured successfully!
Hence, my App ID is tight-limit-8371.
The next sections explain the architecture and code in detail, if you rather skip to
the deployment part, go to the Configure project section.
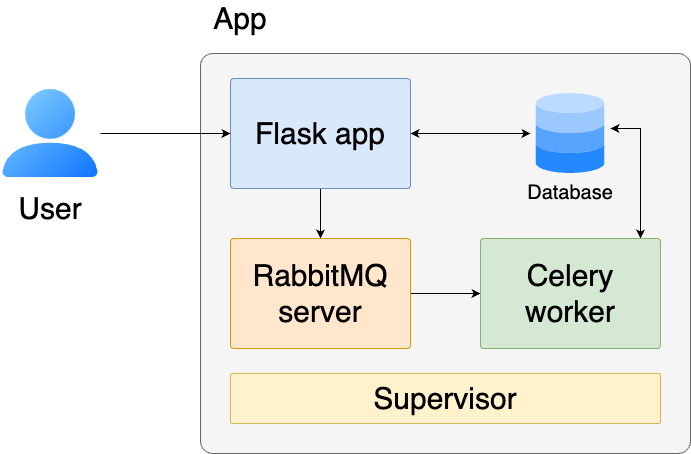
Let’s explain the components of our system at a high-level.
The Flask app receives requests from our users and responds. It’ll ask users to authenticate and offer an interface for them to ask questions about their Google Drive documents.
The Database (SQLite) stores the documents downloaded from Google Drive and the embeddings (using OpenAI)
we compute for each one. It also performs similarity search (via sqlite-vec) so we can retrieve the relevant documents when asking a
question.
Since downloading all files, parsing them and computing embeddings takes some time. We have a job queue that allows us to execute this work in the background. The RabbitMQ server acts as a message broker, storing the background jobs in a queue, while the Celery worker processes these jobs by downloading documents from Google Drive, converting them to markdown, and computing embeddings that we’ll use later for similarity search.
Finally, Supervisor is a process control system that ensures our application components stay running. If any process crashes (like the Flask app or Celery worker), Supervisor automatically restarts it, making our application more reliable and resilient to failures.
app.py)The Flask app (app.py) handles all web requests and user interactions. The most important part is the authentication flow - when users visit /login, we use Google’s OAuth2 flow to authenticate them and get permission to access their Google Drive documents. The callback handler stores their credentials securely in the database:
@app.route("/oauth2callback")
def oauth2callback():
# Get credentials from OAuth flow
flow = Flow.from_client_config(CREDENTIALS, scopes=SCOPES,
redirect_uri=url_for("oauth2callback", _external=True))
flow.fetch_token(authorization_response=request.url)
credentials = flow.credentials
# Store credentials in database
token_info = {
"token": credentials.token,
"refresh_token": credentials.refresh_token,
# ... other token fields ...
}
with Session(engine) as db_session:
user = db_session.query(User).filter_by(email=email).first()
if user is None:
# NOTE: in a production system we must use a secure secrets storage!
user = User(email=email, token_info=json.dumps(token_info))
db_session.add(user)
Once authenticated, users can trigger document loading via the /load endpoint, which starts a background Celery task to process their Google Drive documents. The /search endpoint handles question answering - it takes the user’s query, finds relevant documents using embedding similarity search, and generates an answer using GPT-4o mini:
@app.post("/search")
def search_post():
query = request.form["query"]
answer = answer_query(query, email=session["email"])
return render_template("search-results.html", answer=answer)
The app uses Flask’s session management to keep track of logged-in users and implements a @login_required decorator to protect endpoints that require authentication. All database operations are handled through SQLAlchemy sessions, ensuring proper transaction management and connection handling.
The document loading process is handled by the load_documents_from_user function in load.py. This function first retrieves the user’s stored Google credentials and uses them to initialize both Drive and Docs API clients. It then queries Google Drive for all Google Docs files (excluding trashed items):
query = "mimeType = 'application/vnd.google-apps.document' and trashed=false"
results = drive_service.files().list(
q=query,
pageSize=100,
fields="nextPageToken, files(id, name)",
).execute()
For each document, we fetch its full content using the Docs API and convert it to markdown format using the convert_doc_to_markdown function. This function handles various document elements like headings, bold text, and italics, ensuring the document’s structure is preserved.
The most computationally intensive part is computing embeddings for all documents. We do this efficiently by batching all document contents together in a single API call to OpenAI’s embedding service. Finally, we store or update each document in the database with its content, embedding vector, and metadata:
embeddings = compute_embedding([md[2] for md in markdown_docs], return_single=False)
with Session(engine) as db_session:
for (drive_id, name, content), embedding in zip(markdown_docs, embeddings):
# Update existing or create new document
db_doc = Document(
name=name,
content=content,
embedding=embedding,
google_drive_id=drive_id,
user_id=user.id,
)
db_session.add(db_doc)
The question answering functionality is implemented in answer.py. When a user submits a query, we first compute an embedding vector for their question using OpenAI’s text-embedding-3-small model. This embedding is then used to find the most relevant documents from their Google Drive using similarity search.
The similarity search is implemented in the Document model using SQLite’s vector extensions. The find_similar method executes a SQL query that computes the L2 (Euclidean) distance between the query embedding and all document embeddings stored in the database, returning the closest matches:
@classmethod
def find_similar(cls, session, embedding, user_id, limit: int = None):
query = text("""
SELECT id, vec_distance_L2(embedding, :embedding) as distance
FROM documents
WHERE user_id = :user_id
ORDER BY distance
""" + (f"LIMIT {limit}" if limit else ""))
Once we have the most relevant documents, we send them along with the user’s query to GPT-4o mini through OpenAI’s chat completions API. The documents are formatted as markdown and provided as context, allowing the model to generate an informed answer based on the user’s personal Google Drive content:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant..."},
{"role": "user", "content": "\n\n".join([doc.to_markdown() for doc in similar_docs])},
{"role": "user", "content": query},
],
)
To keep documents up-to-date with changes in users' Google Drive, we use Celery for background task processing. The background.py module defines a periodic task that runs every 60 minutes to check for and process document updates for all users:
@app.on_after_configure.connect
def setup_periodic_tasks(sender: Celery, **kwargs):
# 60 minutes
PERIOD = 60 * 60
sender.add_periodic_task(
PERIOD,
schedule_document_loading,
name="schedule_document_loading",
)
The scheduling process works in two stages. First, the schedule_document_loading task queries the database for all registered users. Then for each user, it asynchronously triggers the load_documents_from_user task which handles the actual document loading process. This task uses the stored OAuth credentials to access the user’s Google Drive, fetch any new or updated documents, and update the database accordingly:
@app.task
def schedule_document_loading():
with Session(engine) as db_session:
users = db_session.query(User).all()
for user in users:
load_documents_from_user.delay(
email=user.email,
limit=50,
)
For simplicity, we’ve implemented a single periodic task that processes all users' documents at once. While this works for demonstration purposes, a production system would benefit from a more sophisticated scheduling approach. Instead of updating all users simultaneously, it would be better to distribute the load by scheduling individual tasks per user at different times throughout the day. This would prevent the task queue from getting overwhelmed and ensure more consistent performance. Additionally, tracking changes at the document level would allow for even finer-grained control, enabling the system to prioritize updates for frequently modified documents while reducing unnecessary processing of static content.
Open the Google Cloud console and create a new project:
Once the process finishes, the notification bar will show up. Click on SELECT PROJECT:
Go to APIs & Services -> Library:
Once the search bar appears, search for the Google Docs API:
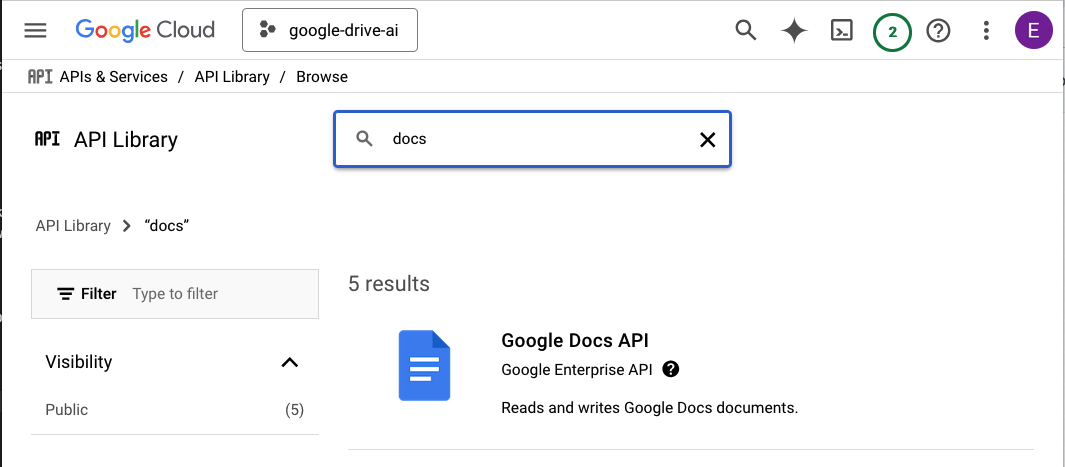
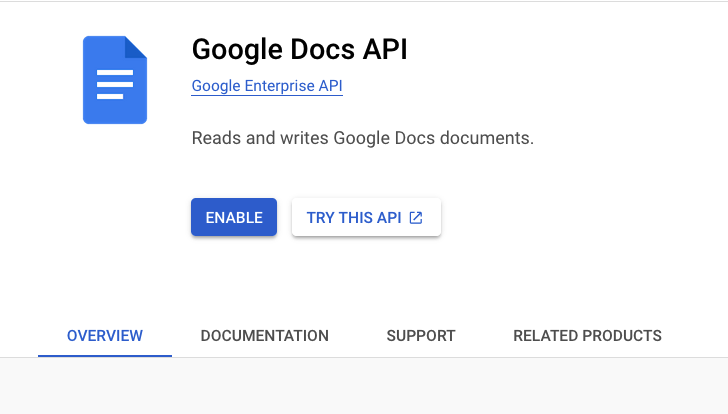
And enable it:
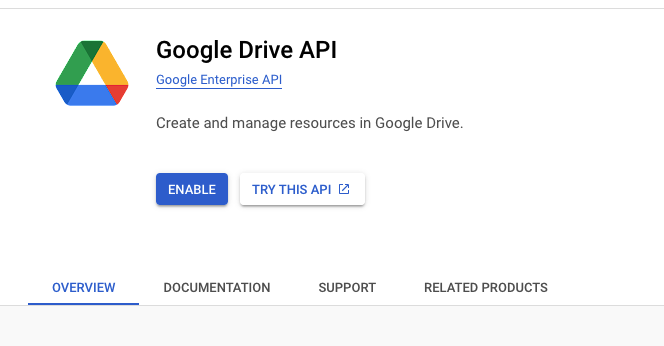
Go back and search Google Drive API, and enable it:
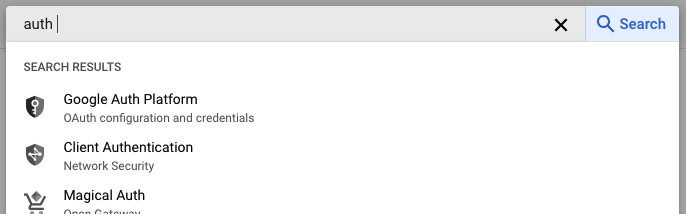
Let’s now configure OAuth. Search auth in the top search bar and click on Google Auth Platform:
You should now see a screen like this, click on Get Started:
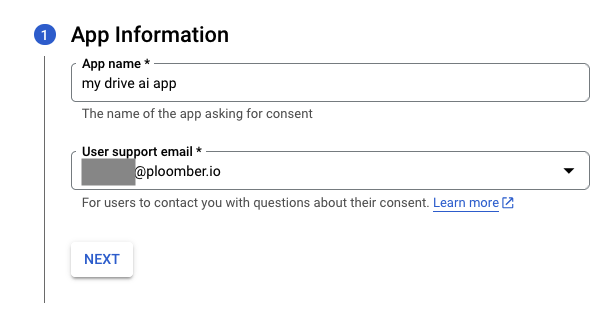
You’ll need to fill out a form with the details of your application. Note that Google has a policy about App name, so write a generic one (if your app name doesn’t comply with the policy, you can try again):
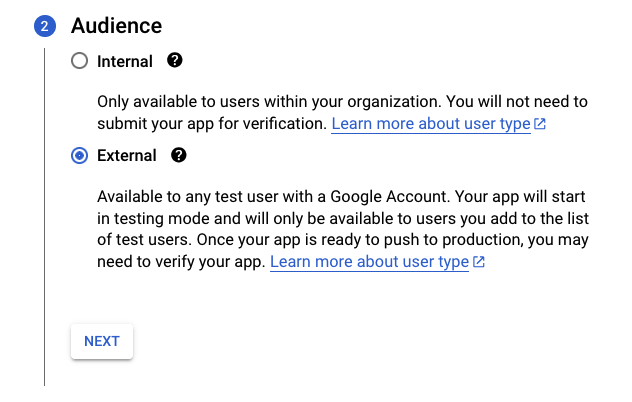
In the Audience section, I recommend selecting External, otherwise, only members of your organization will be able to use the app.
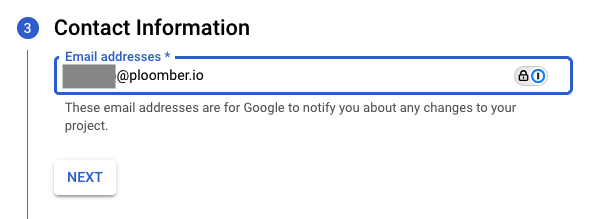
Finally, enter a support email address:
Agree to the User Data Policy and click on CREATE:
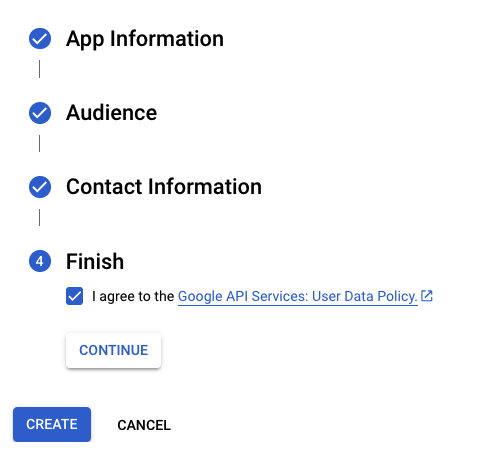
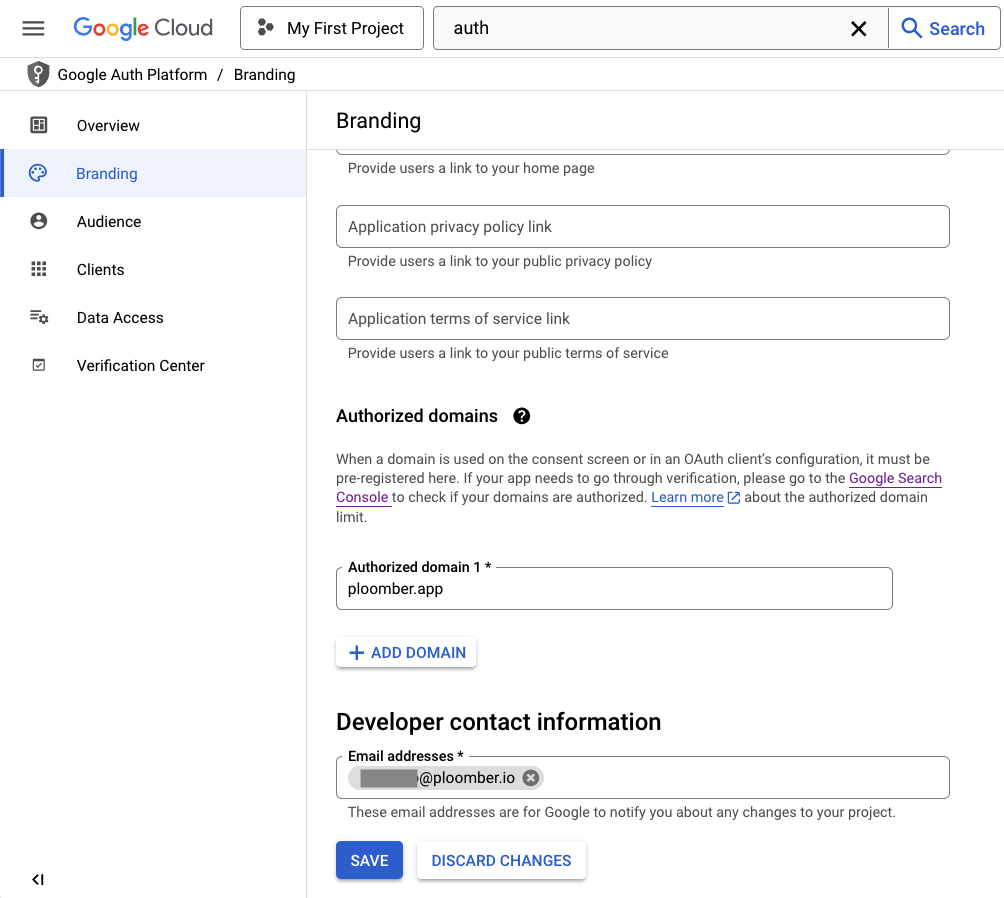
Go back to Google Auth Platform and click on Branding. Scroll down and you’ll see an Authorized domains section, enter ploomber.app:
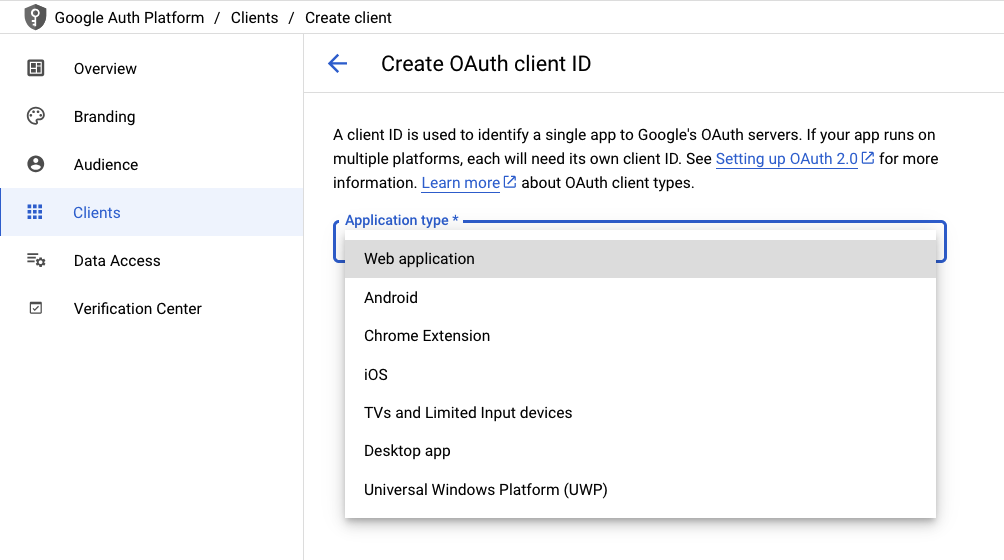
Now, click on Clients (left sidebar) -> + CREATE CLIENT. Select Web application as the Application type.
NOTE: If you encounter a message saying you have to configure the consent screen, ensure you properly configured the Authorized domains in the Branding section and wait for a minute or so.
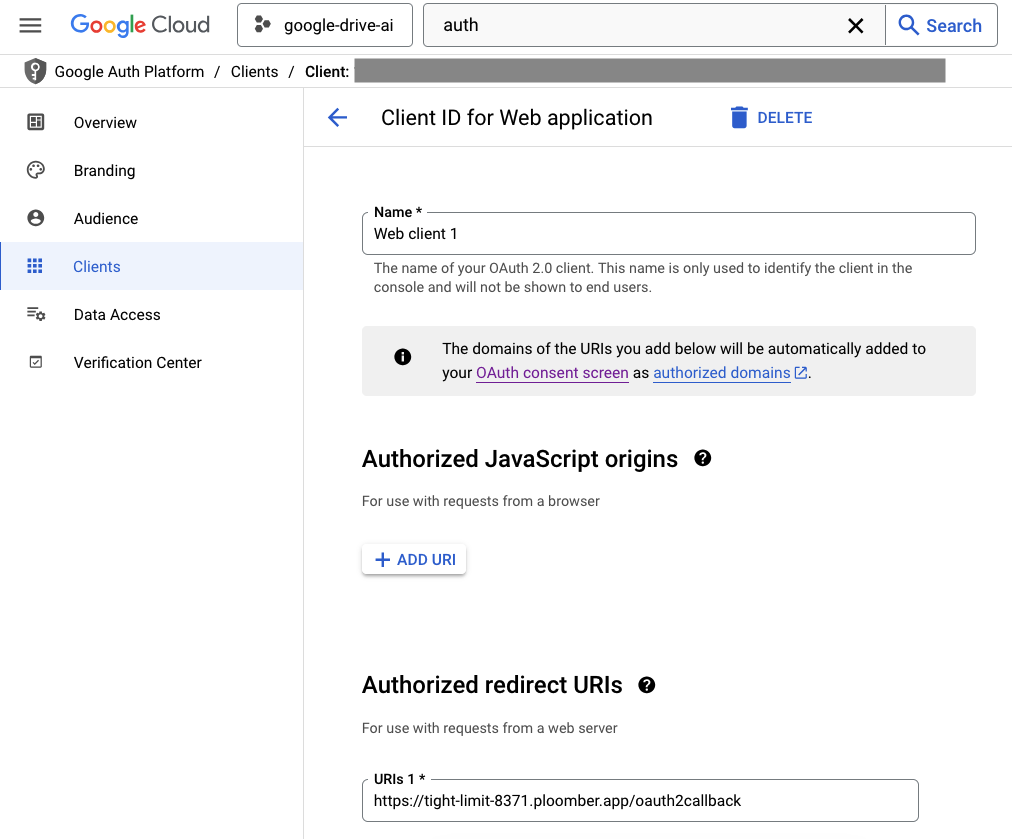
Then, enter a name for your client and go to the Authorized redirect URIs and enter the following:
https://ID.ploomber.app/oauth2callback
Where ID is your Ploomber Cloud App ID. Scroll down and click on SAVE.
Once saved, you’ll be taken to the client list. Click on the arrow pointing downwards in the Actions section:
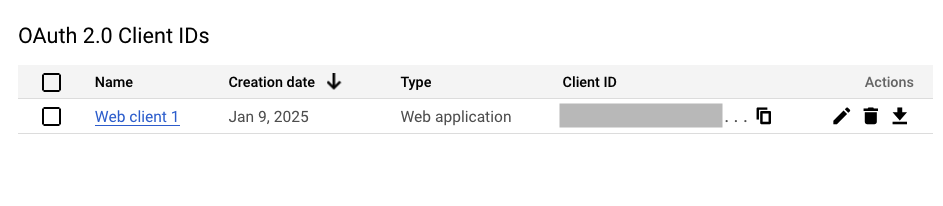
Once the client details are displayed, click on DOWNLOAD JSON:
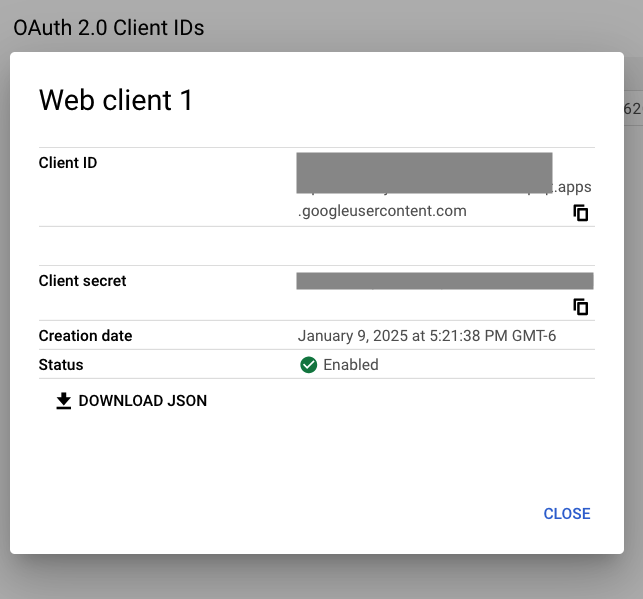
Rename this file to credentials.json and store it in the parent directory of the example code you downloaded earlier.
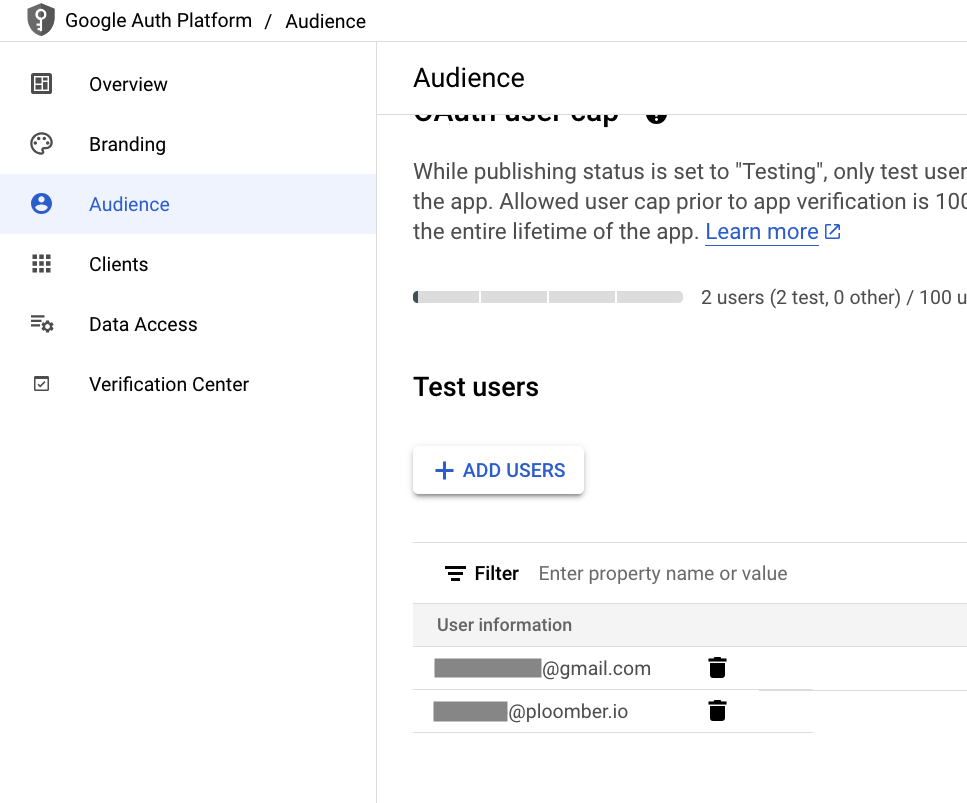
Now, go to the Audience section and add some test users (NOTE: this is only required if you selected External in the audience when creating the app):
Our app is now fully configured on Google Cloud. Let’s now deploy it!
First, we need to ensure the app credentials and OpenAI API key are properly passed to our Flask app. Execute the following in your project’s root directory:
python -m gdrive_loader.env
This will prompt you for your OpenAI key and ensure that there is a credentials.json file (downloaded earlier) in the current directory.
We’re ready to deploy:
ploomber-cloud deploy
The command will print a URL to track progress. After a minute or so, the app will be available:
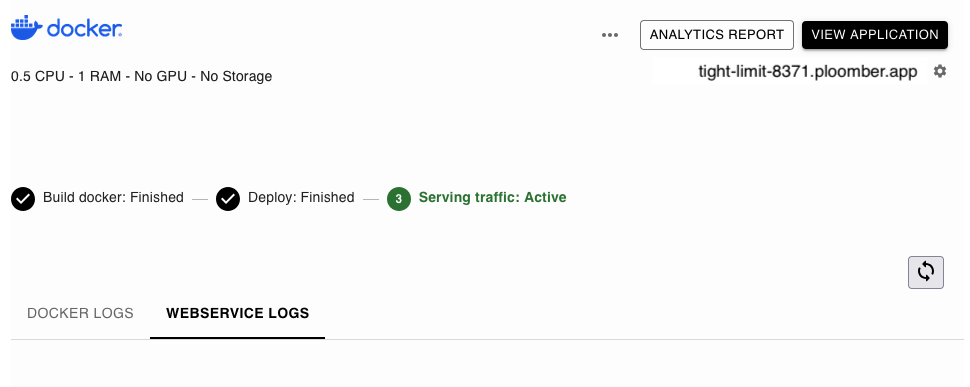
Once that happens, open the app URL and you’ll see this:
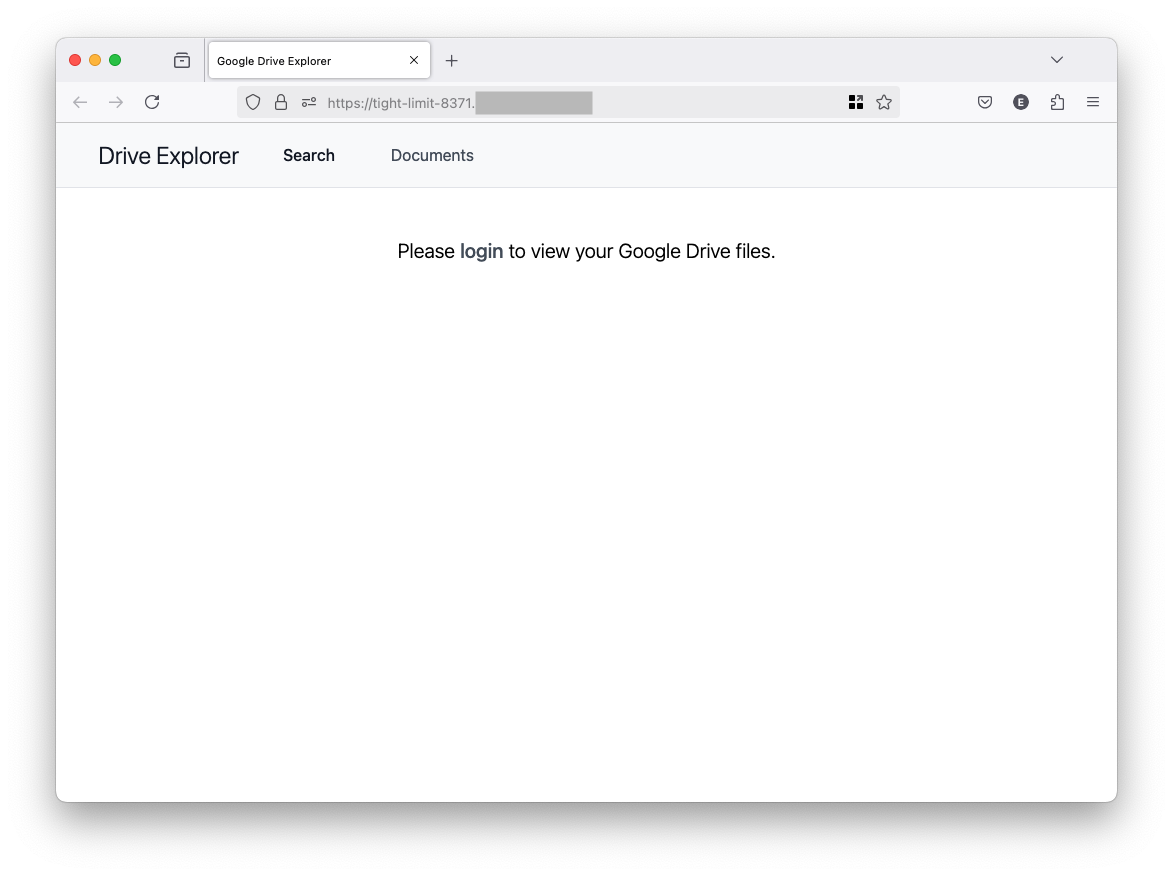
Click on login to authenticate. You’ll see something like this (that’s expected since our app hasn’t been verified as we’re in test mode), click on Continue:
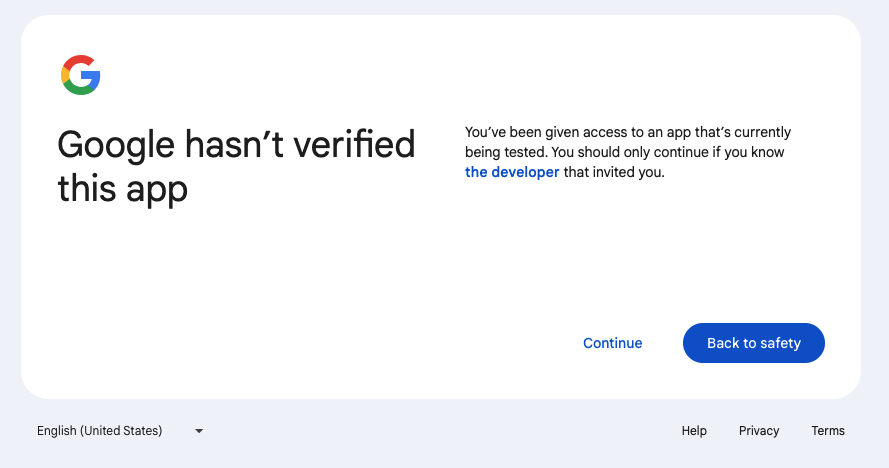
Next, enable all permissions:
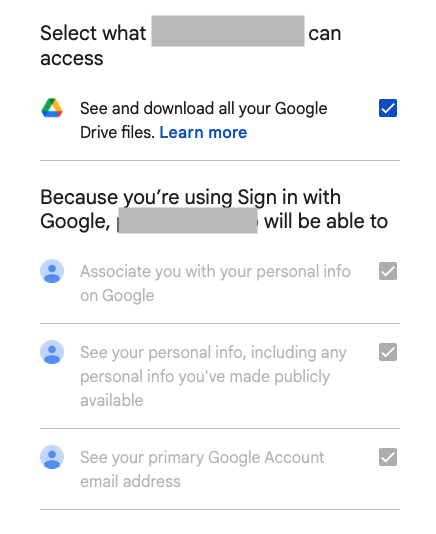
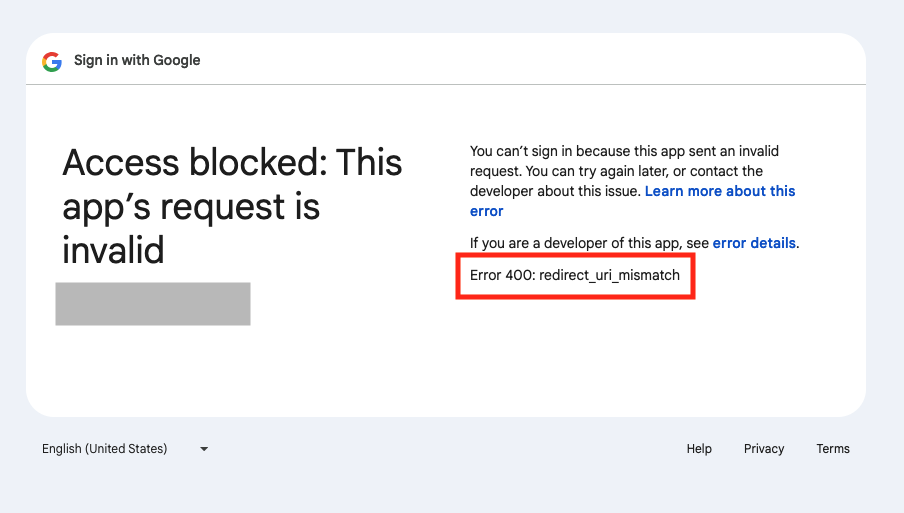
NOTE: if you encounter an error like the one in the image above. Double check the Authorized redirect URIs, it must exactly match the URL from your app:
Once you finish the login workflow, you’ll see the following:
Now, click on Load docs in the top right corner. This will start downloading
documents from Google Drive. The process takes 1-2 minutes.
Once the process is done, you’ll see the documents in the Documents section. You can also track progress from the Ploomber Cloud platform, you’ll see something like this in the logs when processing documents:
2025-01-09T23:40:02.873000 - [2025-01-09 23:40:02,873: WARNING/ForkPoolWorker-2] Saved new document: DOC NAME
And something like this when all documents have been processed:
2025-01-09T23:40:02.883000 - [2025-01-09 23:40:02,883: INFO/ForkPoolWorker-2] Task gdrive_loader.background.load_documents_from_user[xyz] succeeded in 30.0s: None
Finally, click on Search and start asking questions about your documents!
This application is a proof of concept designed to demonstrate the core functionality of integrating Google Drive with AI capabilities. As such, it has several limitations that make it unsuitable for production use. The application lacks important features like proper security measures (tokens aren’t encrypted), and robust error handling for Google Drive API calls. We’ve made some architectural choices to keep things simple, such as not storing complete documents (to stay within model context limits), using a single SQLite database (instead of separating user data), and implementing basic session management. Additionally, the lack of persistent storage means all data is wiped when the app restarts. If you’re interested in deploying a production-ready system that integrates Google Drive with AI capabilities, please reach out to us to discuss our enterprise-grade solutions that address these limitations.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

