


In this blog post, I’ve summarized my findings when asking GPT-4o to generate Flask applications, ranging from a simple Hello, world! app to a full-fledged CRUD app with three database models and HTML pages with Tailwind.
With careful prompting, GPT-4o can produce working Flask applications and follow (some) best coding practices.
My initial system prompt was simple:
You’re a Python developer who can take instructions and generate code. You’ll be described the task at hand. Generate only Python code, do not enclose the code in Markdown code fences (triple backticks)
After I prompted the model to generate some random apps, I thought having documentation to test the app quickly would make the process easier, so I changed the system prompt:
You’re a Python developer who can take instructions and generate code. You’ll be described the task at hand.
Your output must be a JSON string. The keys in the JSON document must be paths to files. The values must contain Python code that can be executed. Do not include markdown code fences.
You must include a main.py file, which should be the entry point for the application. For example, the app should execute when running
python main.py.You must also include a README.md file containing sample commands to use the app; for example, building a REST API should consist of sample curl commands.
With this setup, I started my experiments and asked the model to generate increasingly complex apps.
As a first experiment, I asked GPT-4o to generate a “Hello, world!” application with the following prompt:
Create a Flask app with a single route (/) that returns a JSON response with a key of ‘message’ and a value of ‘Hello!’
I ran this three times (with default parameters) and noted that the Python code was identical in two responses. And the one different response only differed in the name of the function:
@@ -3,7 +3,7 @@
app = Flask(__name__)
@app.route('/')
-def hello():
+def home():
return jsonify({'message': 'Hello!'})
if __name__ == '__main__':
Furthermore, the requirements.txt was the same in all three results; however, the README.md slightly differed. The three apps ran as expected.
Note that I had to clean the model’s response in two of three cases because even though the system prompt explicitly asked to skip the Markdown code fences, they still appeared. So, I wrote a function to clean them up.
For my second experiment, I asked GPT-4o to generate a more sophisticated application that required writing a database model and more API routes, this was the user prompt:
Create a Flask app with CRUD endpoints for a Book model. The book model has the following fields: title, author, and year_published.
I ran the experiment three times and realized that the model also generated a requirements.txt file (even though I didn’t ask for one!). I modified my testing code to run each app in an isolated virtual environment, and install all packages from the generated requirements.txt, which caused all apps to break. Upon investigation, I noted that the requirements.txt installed an old Flask version (incompatible with the code). So I modified the system prompt and added this:
You must also include a requirements.txt file that contains all the dependencies. Only specify the package name, not the version number, e.g., flask, not flask==1.1.1.
I re-ran the experiment. Here are the results.
GPT-4o generated a SQLite-backed application (even though I didn’t specify which database to use). More interestingly, the names of the files differed. They all had a README.md, requirements.txt and a main.py but the app was organized differently:
app/ directory with the routes in app/book.py, and the DB model in app/models.pyapp/ directory, with the routes in app/routes.py and the DB model in app/models.pysrc/ directory, with models under src/database.py and the DB model in src/models.pyOne of the three generated apps was broken because it wasn’t initializing the database model correctly (it used flask-sqlalchemy).
The second app worked as expected but made an odd choice of using both flask-sqlalchemy and flask-marshmallow; adding the latter seemed unnecessary as it didn’t provide significant value for such a simple application.
One app worked as expected: it properly initialized flask-sqlalchemy, the API worked correctly, and the README.md contained accurate curl commands. The code was clean and organized. The only minor issue I found is that it returned an HTML (instead of JSON) response when trying to edit or delete non-existing books.
The third experiment involved creating a REST API with two database models:
Create a Flask app with CRUD endpoints for a Book and an Author model. The book model has the following fields: title, author_id, and year_published. The Author model has the following fields: name, and date_of_birth. author_id is a foreign key to the Author model. Creating a new Book should require the author_id to be passed in the request.
I ran the experiment three times; these are the results.
Two applications were broken because they received the date_of_birth as a string, but the app failed to store it in the database since SQLite was expecting a Python datetime.date object. Furthermore, in one of these two broken apps the README.md didn’t contain working curl commands; it just described the endpoints (in the other application, the README.md container the proper curl commands)
The final application had an issue because it generated an incorrect database model:
class Book(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(100), nullable=False)
author_id = db.Column(db.Integer, db.ForeignKey("author.id"), nullable=False)
year_published = db.Column(db.Integer, nullable=False)
author = db.relationship("Author", backref=db.backref("books", lazy=True))
As you can see from the previous snippet, the author variable isn’t indented, causing the book endpoints not to include the author’s information:
[
{
"id": 1,
"title": "title a",
"year_published": 2020
},
{
"id": 2,
"title": "title b",
"year_published": 2024
}
]
Adding indentation fixes the issue.
Another error I found is that the application stores the author’s date_of_birth column as a string instead of a date; that’s why it doesn’t have the issue the first two applications have, but it’s not a great way to fix it.
To see if I could hint GPT-4o how to handle date columns, I added the following to the system prompt:
If a model contains a date column, you must store it as a date in the database:
class SomeModel(db.Model): some_date = db.Column(db.Date, nullable=False)Then, when authoring the API code, you can use the following code to parse the string submitted by the user and turn it into a date object:
from datetime import datetime date_submitted = datetime.strptime('2014-12-04', '%Y-%m-%d').date()Note that you might need to change the second argument passed to strptime based on the date string format you’re parsing.
I re-ran the experiment, and it generated a working app that correctly handled the date column!
I noted that the SQLAlchemy models use the old Column API. SQLAlchemy recently changed its API, and it now recommends using mapped_column. Even flask-sqlalchemy’s documentation shows an example using mapped_column:
from sqlalchemy import Integer, String
from sqlalchemy.orm import Mapped, mapped_column
class User(db.Model):
id: Mapped[int] = mapped_column(primary_key=True)
username: Mapped[str] = mapped_column(unique=True)
email: Mapped[str]
I wasn’t surprised by this. Since this is a new-ish API change, it’s expected that GPT-4o has way more training data using Column than mapped_column. The application still works as expected as the API is still supported, but it highlights one caveat of “generalist” models: they’re prone to use legacy APIs.
For the next experiment, I asked GPT-4o to generate HTML forms to manipulate the data, instead of generating a REST API:
Create a Flask app that allows performing CRUD operations for a Book and an Author model. The book model has the following fields: title, author_id, and year_published. The Author model has the following fields: name, and date_of_birth. author_id is a foreign key to the Author model. Creating a new Book should require the author_id to be passed in the request.
Generate the necessary HTML forms to create a new book and author. Also, create list views to display all books and authors. List views should also have links to edit and delete the records.
The first app successfully initialized, and opening the / on my browser redirected me to /books, the list view for the Book model. Unfortunately, the navigation was broken, and there was no link to go to /authors (I figured out the route by inspecting the source code). I performed all CRUD operations on Author; however, the app failed when storing a new Book. Upon inspection, I noted that the Book model was wrong:
class Book(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(100), nullable=False)
author_id = db.Column(db.Integer, db.ForeignKey('author.id'), nullable=False)
year_published = db.Column(db.Integer, nullable=False)
As you can see, the Book model is missing the author field. Hence, after a Book is stored, the /books route breaks because the HTML template tries to render the Author’s name for such a book, which doesn’t exist.
The second application returned 404 when opening /, and I had to inspect the code to realize that the HTML routes are /books and /authors. Interestingly, both /books, and /authors contain links to each other, which helps the user navigate between the sections.
The application has barebones HTML forms, and all operations worked except for the Author delete operation, which threw a database constraint error:
sqlalchemy.exc.IntegrityError: (sqlite3.IntegrityError) NOT NULL constraint failed: book.author_id
[SQL: UPDATE book SET author_id=? WHERE book.id = ?]
[parameters: (None, 1)]
(Background on this error at: https://sqlalche.me/e/20/gkpj)
One interesting thing I noted is that the form for adding a new Book contained a dropdown to select an Author:
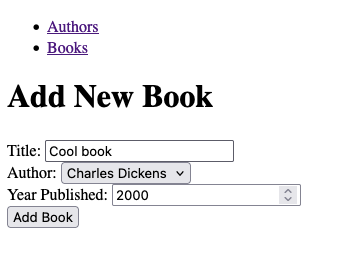
This is nice from a UX perspective since it allows the user to choose an Author by name; however, the implementation wasn’t great because it fetches the entire author table:
@book_bp.route('/new', methods=['GET', 'POST'])
def new_book():
authors = Author.query.all() # fetching an entire table!
if request.method == 'POST':
# code to handle submission (redacted for brevity)
...
return render_template('new_book.html', authors=authors)
The final app was the most interesting: it added Tailwind (even though the prompt didn’t ask for it) which caused the app to look much better (the following images only show the Book views since the Author views looked the same):
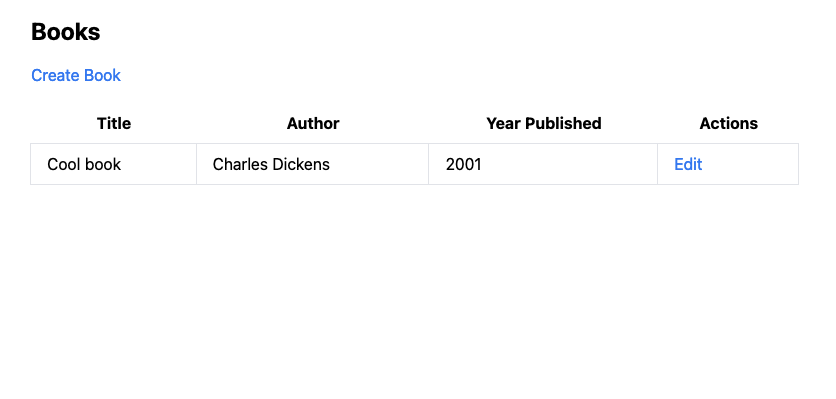

All the operations work except for deletion: there is no button to delete! (and there is no backend code to do it, either). Funny enough, both the Book and Author list views contain the following:
<!-- Add delete link here as needed -->
This was the first experiment in which GPT-4o didn’t generate a fully functional app (based on the specification). But I wanted to experiment a bit more, so I ran two more experiments.
I modified the previous prompt so it asked for confirmation when deleting an author (since this should trigger deleting all books associated with such an author) and to handle book covers:
Create a Flask app that allows performing CRUD operations for a Book and an Author model. The book model has the following fields: title, author_id, and year_published. The Author model has the following fields: name, and date_of_birth. author_id is a foreign key to the Author model. Creating a new Book should require the author_id to be passed in the request.
Generate the necessary HTML forms to create a new book and author. Also, create list views to display all books and authors. List views should also have links to edit and delete the records.
When deleting an author, all books associated with that author should also be deleted. You must ask for confirmation before deleting the author.
Allow uploading an optional image for the book cover. The image should be stored in the database as a BLOB. The image should be displayed on the book detail page.
I’m storing the images in the database to keep things simple.
I ran the experiment three times, which resulted in three broken applications due to an error when rendering the image in the book view, as it contains the following:
<img src="data:image/jpeg;base64,{{ book.cover_image | b64encode }}" alt="{{ book.title }} Cover Image">
Flask uses Jinja to handle HTML templates; however, there is no b64encode filter, which causes this template to break. I modified the system prompt and added the following:
If you store an image BLOB in the database, you can use the following code to convert
the image to a base64 string:
```python
import base64
image_base46 = base64.b64encode(object.property).decode()
```
Then, you can pass this to the render_template function in Flask to display the image:
```python
@app.route('/some-route')
def some_route():
return render_template('some_template.html', image_base64=image_base64)
```
And in the template, you can display the image like this:
```html
<img src="data:image;base64,{{ image_base64 }}">
```
I re-ran the experiment another three times; these are the results.
One application was broken (it had an indentation error).
The second application worked well! All operations were performed as described (even the book cover was displayed), and navigation was correct, with links to books and authors. Deletion also worked, and it asked the user for confirmation! A fully functional app!
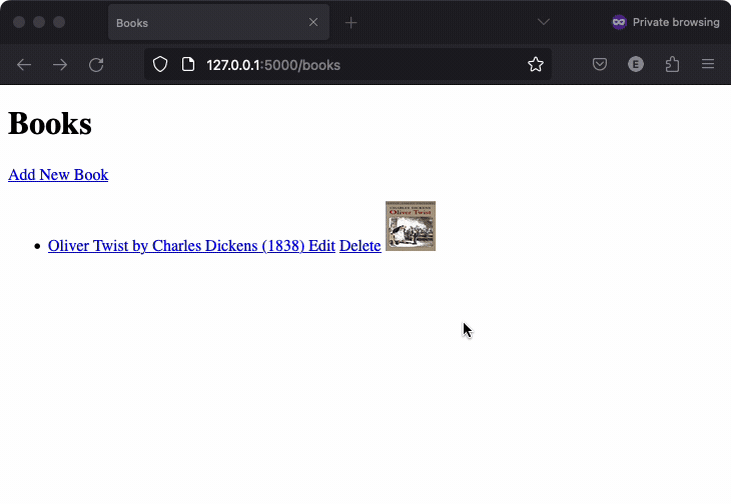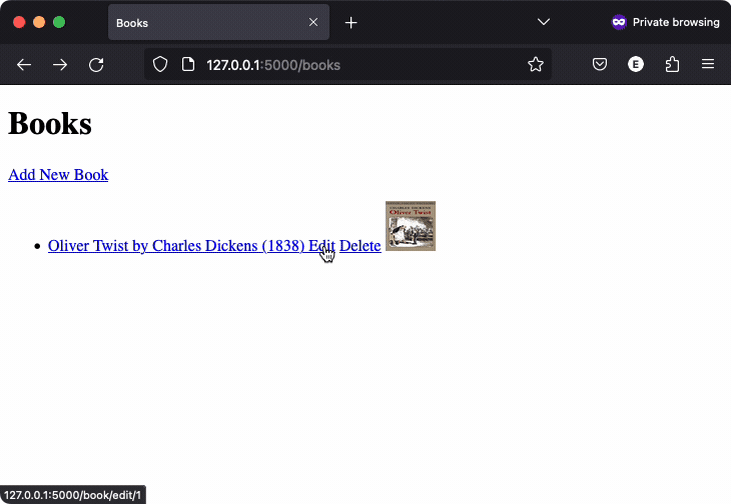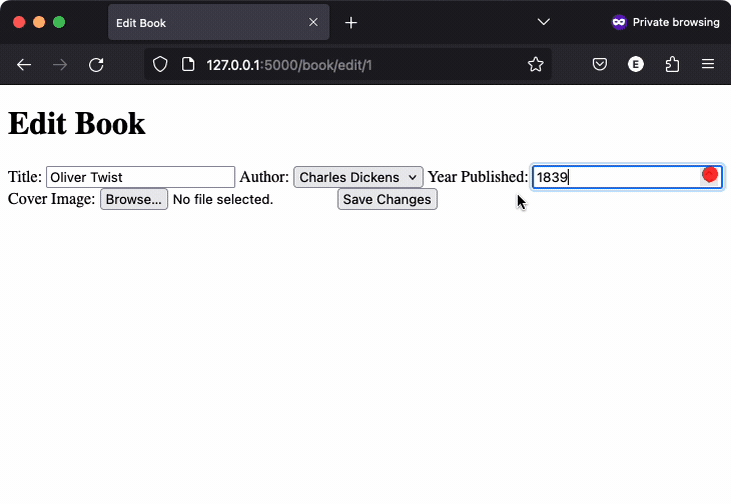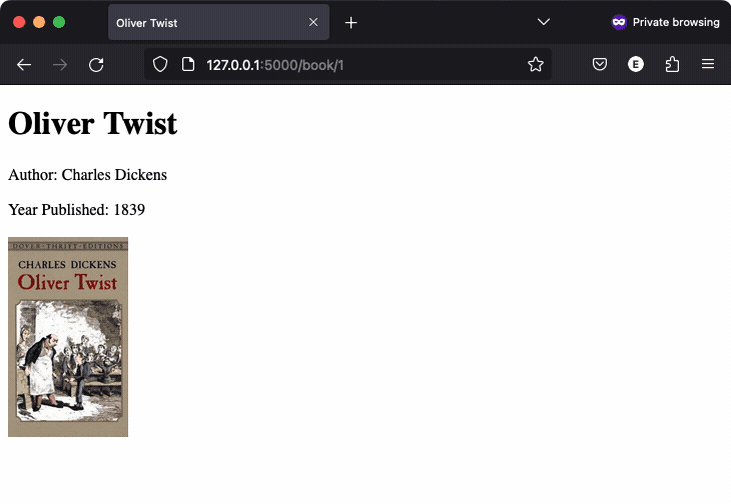
The third application worked almost as well, but it had a minor issue: navigation was broken. / takes you to /authors, but there is no way to go to /books. Interestingly, the img tag generated to display the book cover set a max width and height of 200px in the detail view and 50px in the list view, here’s a video recording:
As a final experiment, I asked GPT-4o to generate a new application; this time, I changed a few things.
First, I modified the system prompt to ask for proper navigation links and to use Tailwind:
If you’re asked to build HTML content, ensure proper navigation between the pages. And use Tailwind CSS to style the HTML content.
Secondly, I changed the database models and asked to generate an app requiring three database models. The user prompt is as follows:
Create a flask app that allows performing CRUD operations for models: Artist, Album, and Song. Artist has the following fields: name, date_of_birth. Album has the following fields: title, artist_id, and year_released. Song has the following fields: title, album_id, and duration. album_id and artist_id are foreign keys to the Album and Artist models, respectively.
Creating a new Album should require the artist_id to be passed in the request. Creating a new Song should require the album_id to be passed in the request.
When deleting an artist, all albums and songs associated with that artist should also be deleted. When deleting an album, all songs associated with that album should also be deleted. You must ask for confirmation before deleting the artist or album.
Generate the necessary HTML forms to create a new artist, album, and song. As well as list views to display all artists, albums, and songs. List views should also have links to edit and delete the records. Displaying an artist should display all albums and displaying an album should display all songs.
Allow uploading an optional image for the album cover. The image should be stored in the database as a BLOB. The image should be displayed on the album detail page.
This generated two broken applications because I hit the maximum token limit, which cut off the JSON response and generated an invalid JSON string.
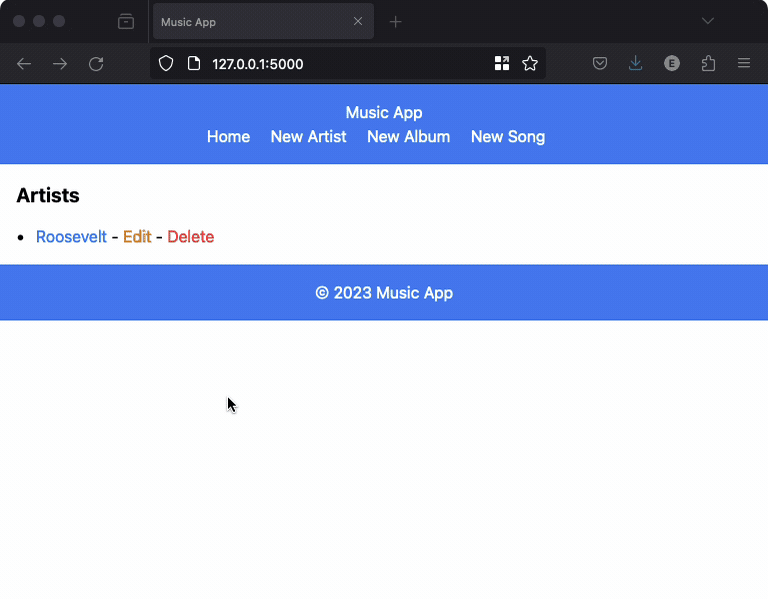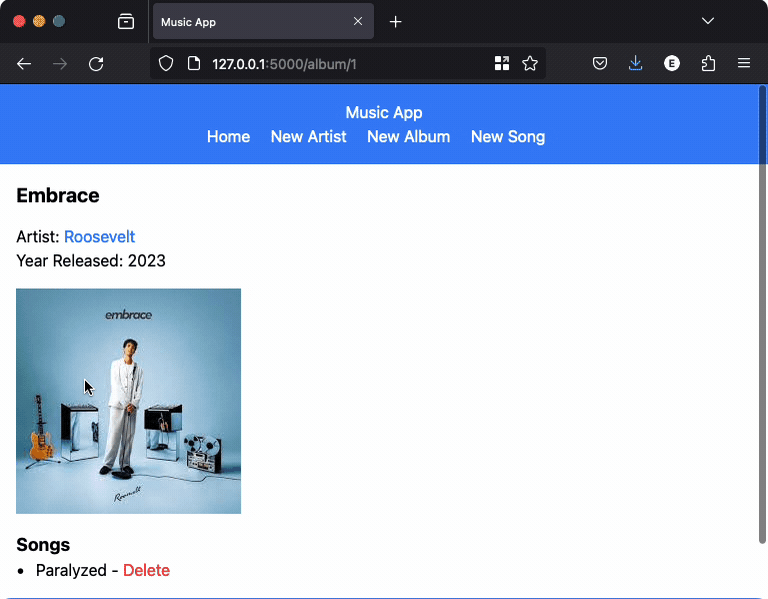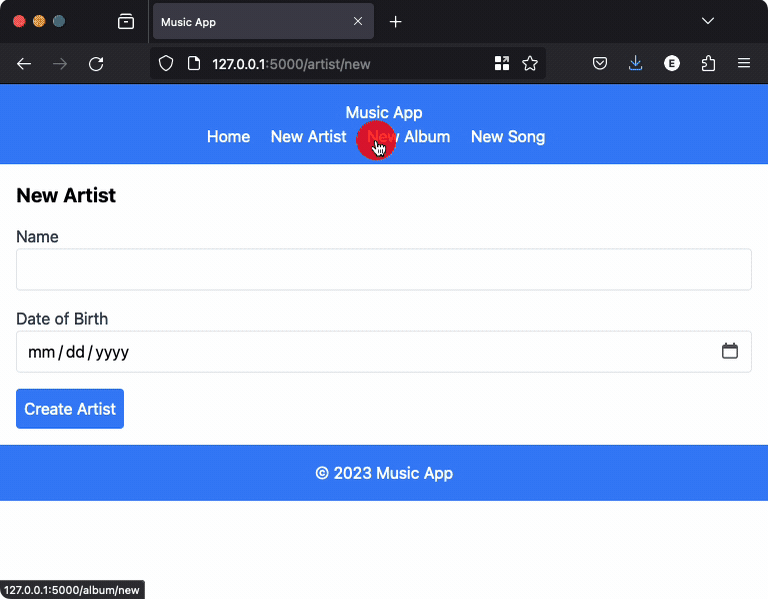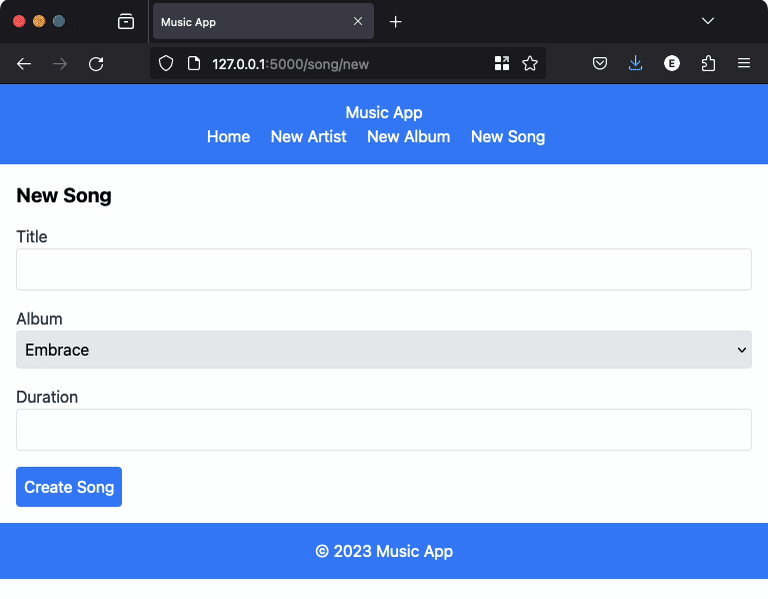
However, it generated a valid app: all operations worked except for the edit operations. The edit artist operation was broken, and the edit album and edit song operations were missing. Here’s a recording of the app:
I was pleasantly surprised by the generated quality code: it was clean, organized, and followed (some) best practices. I’m excited about the future of AI-assisted programming as I can boost engineers' productivity by quickly generating boilerplate code. For example, generating database models takes me way more than GPT-4o because I must keep checking the documentation and generating CRUD endpoints or base HTML templates.
At this point, it’s unclear how well this model will generate more complex code (for example, ask to store images in S3 or create an authentication mechanism), but the current AI is the worst AI we’ll use, so I’m confident that AI will be able to take on more and more complex tasks.
One thing to note is that there’s much more we can do even with the current GPT-4o model. The most significant limitation of the described approach is that it only asks for user input once: it’s a one-off process where the user cannot provide further feedback. A better system would ask the user for an initial prompt, the model would generate the code, the user would test the app and then point the system to fix any issues or add new features.
Another problem is the output token limit, which we already hit twice in the last experiment. An alternative approach would be to ask GPT-4o to break the initial prompt into multiple parts and perform various requests (one for each part) so we don’t hit the limit.
I’m excited about the productivity boosts that LLMs are bringing to programming; I already use GitHub Copilot daily, and it provides a non-negligible productivity boost. My main limitation is that it knows “a bit of everything” and often makes mistakes when I ask for complex stuff. I believe specialized models (with careful prompting or fine-tuned) can do a much better job at working with specific frameworks (for example, a model that’s been prompted to develop Flask apps following best practices)
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

