



Hacktoberfest is an annual event that takes place every October (typically on a remote basis), celebrating and promoting open source collaboration. It encourages people of all skill levels to contribute to open source projects, fostering a community of developers, writers, designers, and more. Participants are encouraged to make contributions to open source repositories hosted on platforms like GitHub, and those who meet the challenge criteria typically earn rewards or recognition for their contributions.
Open source refers to a type of software where the source code is made freely available for anyone to view, modify, and distribute. This model promotes collaborative software development, allowing communities to build upon each other’s work, innovate rapidly, and share knowledge.
Open source is vital for several reasons:
At Ploomber, we recognize the importance of open source and community building as central aspects of our brand identity. We are committed to supporting open source projects and initiatives, and we are excited to announce our participation in Hacktoberfest 2023. In this blog we share our experience hosting a 5 week free mentorship program for Hacktoberfest 2023, where we guided participants in the creation of RAG and ETL pipeline using open source technologies.
In October 2023, the Ploomber team provided a mentorship opportunity that included practical training in data engineering, analysis, storytelling, and deployment, culminating in a refined project that demonstrated the participants' software engineering skills, dependency management and application development.
The program was designed to be a flexible five-week mentorship focused on the latest technologies in data science, leveraging advanced large language models and open-source tools to create cutting-edge solutions. It aimed to attract enthusiasts in data science, analytics, and engineering, particularly those keen on practical development.
Key characteristics of the program included:
The program offered two main project options for participants:
Retrieval-Augmented Generation (RAG) is an innovative approach in the field of artificial intelligence that enhances the capabilities of generative models (LLMs like OpenAI’s GPT and transformer models like those hosted on Hugging Face).
RAG operates by integrating a retrieval step into the generative process, where the model first seeks out relevant information from a corpus of documents before attempting to generate an output. This process leverages large databases or knowledge bases, retrieving pieces of information that serve as context or factual grounding for the generation task.
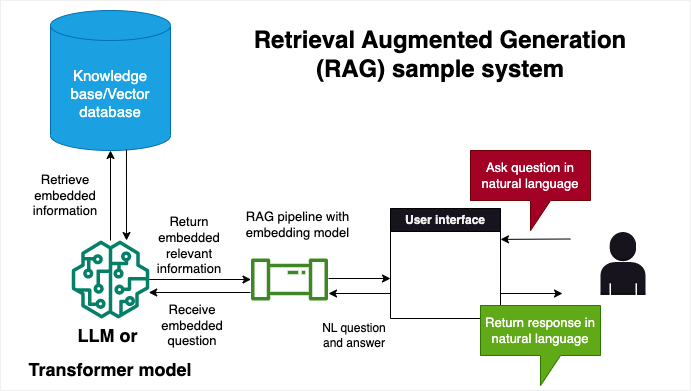
The result is a generative model that is more informed, accurate, and contextually relevant, capable of producing outputs that are not only coherent but also rich with detail and grounded in real-world knowledge. This approach is particularly useful for tasks that require a high degree of specificity, such as question answering, summarization, and translation and its advantages include cost effectiveness compared to fine tuning an LLM or transformer model, as well as reduction in hallucinations, a common phenomenon in LLMs in which an LLM produces incorrect or nonsensical outputs.
Extract Transform Load (ETL) and Extract Load Transform (ELT) are two popular methods to manage raw data and automatically process it so that it is ready for consumption.
ETL is a process in which data is extracted from a source, transformed into a format that is suitable for analysis, and loaded into a target database. ELT is a process in which data is extracted from a source, loaded into a target database, and then transformed into a format that is suitable for analysis.
The ETL process is a common method for data warehousing, which involves extracting data from multiple sources and loading it into a central repository. The ELT process is a common method for data lakes, which involves extracting data from multiple sources and loading it into a central repository.
RAG and ETL are two different approaches to data processing. RAG is a method of generating text through a combination of LLMs grounded on a corpus of documents, while ETL is a method of extracting, transforming, and loading data into a database. However, ETL may be used as part of a RAG pipeline as raw documents are prepared for ingestion into a NoSQL database or a vector database.
The process of preparing documents so they may be used by an LLM mirrors classic ETL and ELT approaches in that a given collection of documents needs to be cleaned (remove outdated information, remove duplicate documents), processed (tokenize, lemmatize, remove stop words), and loaded into a database (NoSQL, vector database).
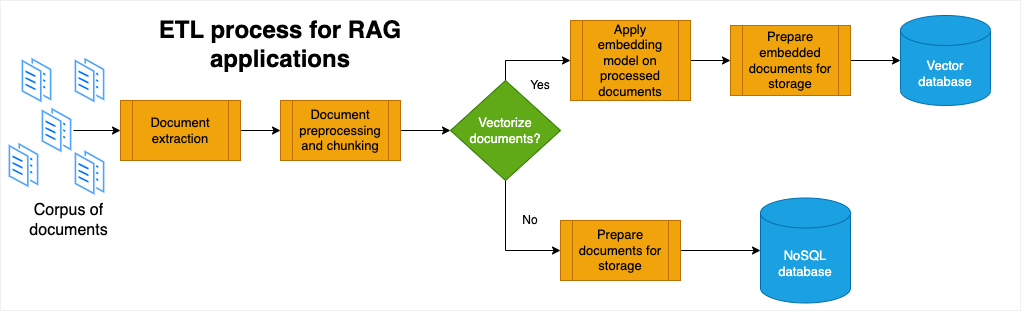
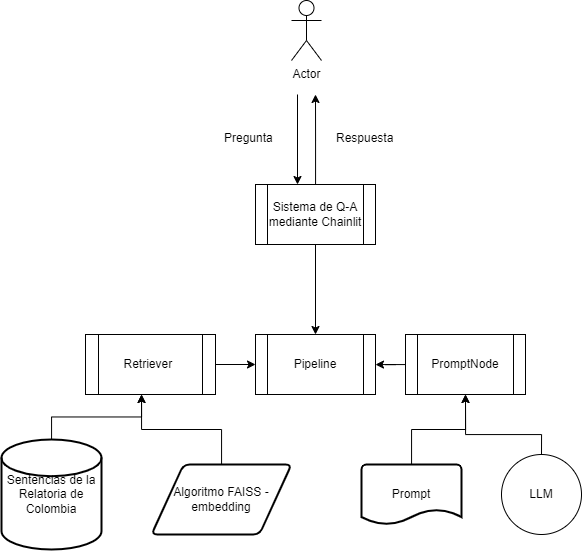
Once a knowledge base such as a NoSQL or vector database is initialized, the next step is to connect it to a Large Language Model (LLM) such as OpenAI’s GPT models, or to a transformer model using Hugging Face’s Python API. This is where the RAG process begins, as the LLM is now able to retrieve relevant information from the knowledge base and generate outputs that are grounded in real-world knowledge.
To enable participants to build ETL and RAG processes and applications, we introduced them to several open source frameworks and tools, including:
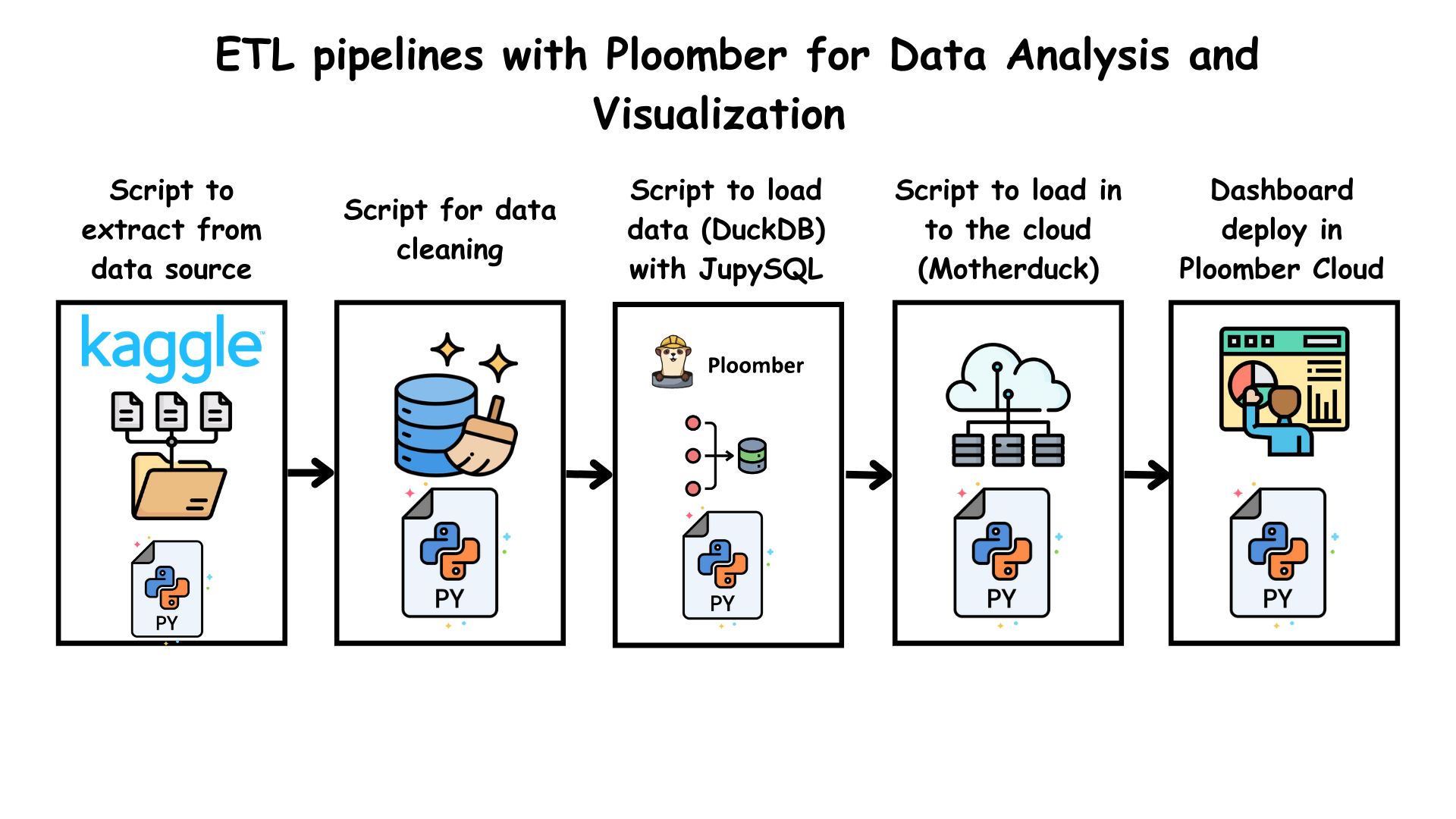
Ploomber: A Python library for reproducible and maintainable pipelines. This is our in-house framework for building data pipelines, which we use to build our own products and services. It is designed to be flexible and extensible, allowing users to build pipelines that are easy to maintain and scale. Users write their Python scripts and Jupyter notebooks, and indicate the order in which they are executed using YAML files.
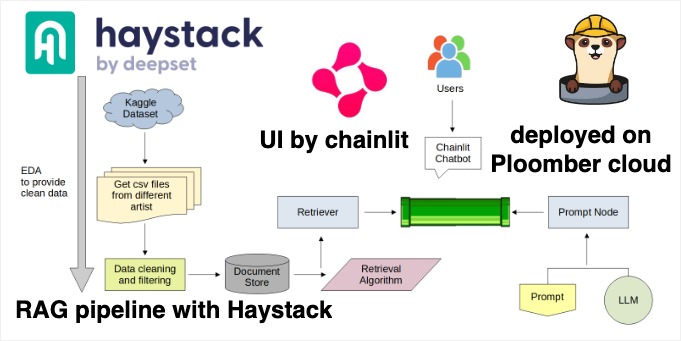
Haystack, by deepset: An LLM orchestration Python framework for building end-to-end question answering systems. It is designed to be flexible and extensible, allowing users to build pipelines that are easy to maintain and scale.
DuckDB and MotherDuck: DuckDB is an in-process SQL OLAP database management system that is designed to be embedded into applications. It is designed to be flexible and extensible, allowing users to build pipelines that are easy to maintain and scale. MotherDuck is a Python library that allows users to deploy cloud based duckDB instances.
FAISS: FAISS is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning. FAISS is written in C++ with complete wrappers for Python/numpy. Some of the most useful algorithms are implemented on the GPU. It is developed by Facebook AI Research. Haystack has a document store integration to enable RAG pipelines.
Weaviate: Weaviate is an open-source, cloud-native vector search engine that allows users to build applications that can find relevant information based on its similarity to other data. It is designed to be flexible and extensible, allowing users to build pipelines that are easy to maintain and scale. Haystack has a document store integration to enable RAG pipelines.
Hugging Face: Hugging Face is a company that develops open-source libraries for Natural Language Processing (NLP) and Deep Learning. Haystack supports local usage of transformer models as well as models hosted on Hugging Face’s model hub.
OpenAI: OpenAI is an artificial intelligence research laboratory that aims to promote and develop friendly AI in a way that benefits humanity as a whole. Haystack supports usage of their LLM models via their API key authentication system.
Streamlit: Streamlit is an open-source Python library that makes it easy to create and share beautiful, custom web apps for machine learning and data science.
Voila: Voila is an open-source Python library that makes it easy to transform Jupyter notebooks into web applications.
Chainlit: Chainlit is an open-source Python package that makes it incredibly fast to build Chat GPT like applications with your own business logic and data.
Docker containers: a Docker container is a standardized unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
Ploomber Cloud: Ploomber Cloud is a cloud-based service that allows users to easily deploy and manage dockerized applications (Flask, Streamlit, FastAPI, Chainlit and more) as well as Voila apps.
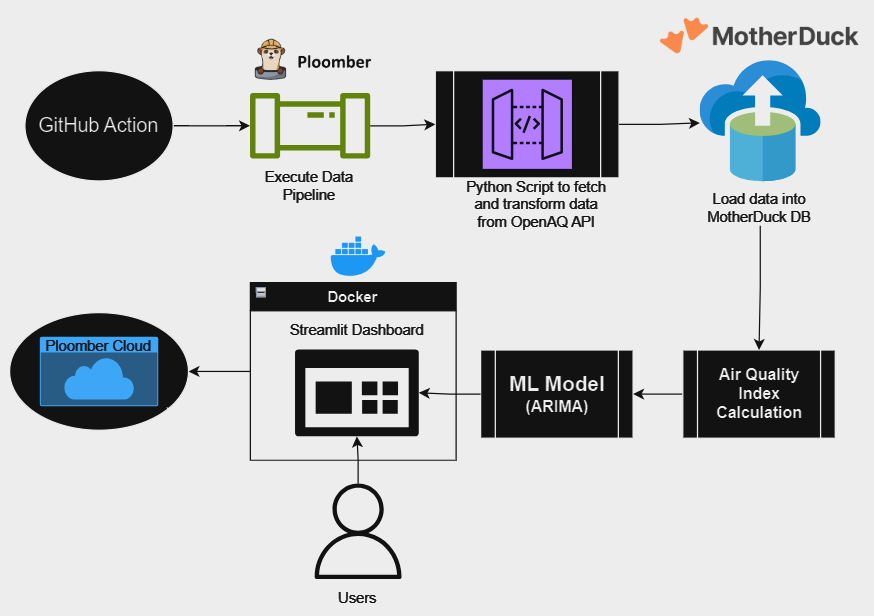
yfinance API that populates a MotherDuck instance, followed by data cleaning, data visualization, and predictive modelling. This project’s goal is to create a predictive model that can analyze historical stock data, market trends, and other relevant factors. This model will provide insights into Microsoft’s stock price movements, offering investors a valuable resource to make smarter investment choices in uncertain times. The team performed EDA on the data fetched from the MotherDuck instance, and experimented with various ML approaches. Their EDA notebook was deployed as a Voila application.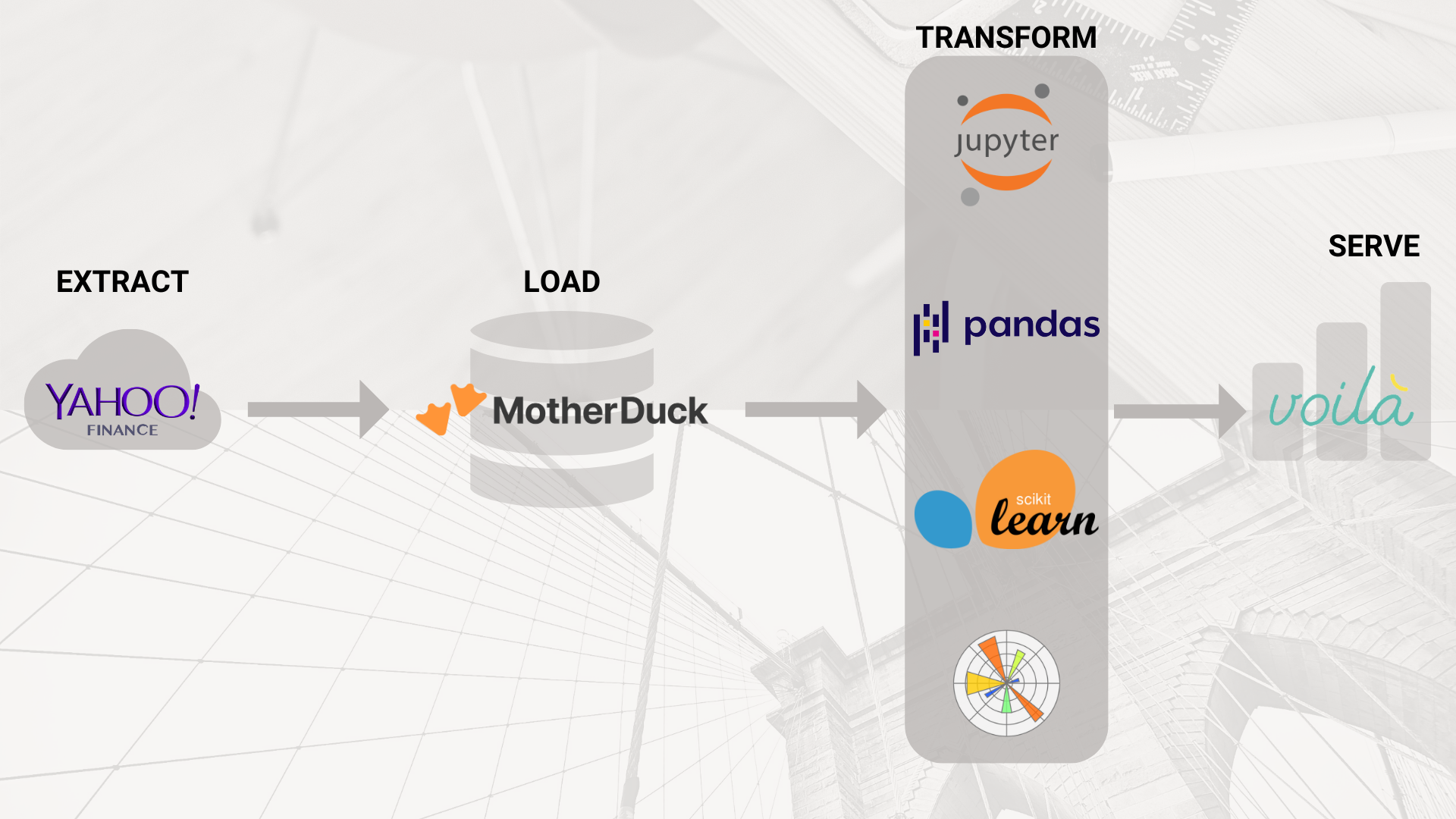
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.


{kind=link}