



Have you ever scrolled through your feed and felt that technological news dominated it? Or you read business-related news, but missed the HN flair? When reading HN I often find interesting economics articles, so I was wondering if it would be possible to add topic filtering.
The key idea:
A special thanks to Ido Michael (@idomic) for reviewing/editing this article!

Side story: I had the idea in 2020, back then I used AWS Sagemaker. Which created a convenient and accurate model. But running a GPU model basically drained all my 10,000$ worth of AWS credits in a year without notice.
Absolutely, there are extremely small models that are distilled versions of language models. 2020 we had distillbert with a size of 250MB. Now there is tinyBert with a size of 70MB. These models can run on CPU for interference. To minimize the costs further it has become simple to deploy it serverless.
Ploomber, Jupyter, Colab, AWS, Python, HuggingFace, React
Steps:
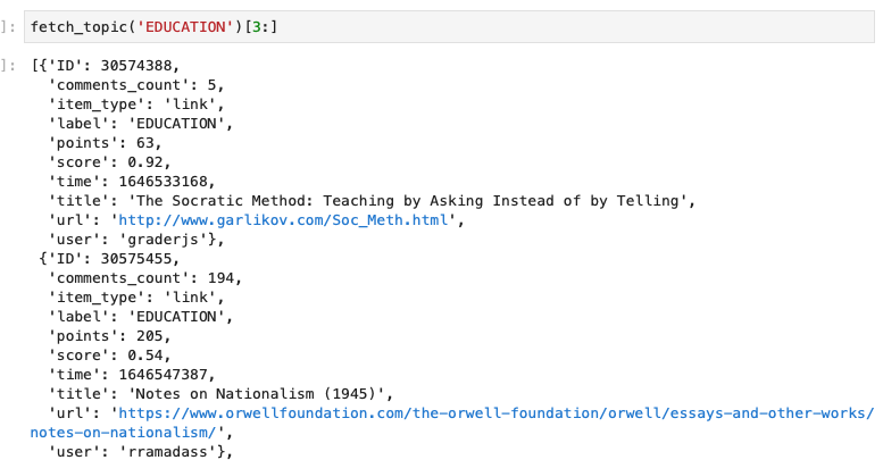
We found a Reuters dataset with over 15 topics on Kaggle (example: ‘Universities starts lectures remote’ Label: ‘Education’). To make things easier, We made the decision to bundle the labels and reduce the total categories to 5 labels. You play around with an example topic classification model here: https://huggingface.co/mrm8488/distilroberta-finetuned-age_news-classification
Now it’s time to balance the data and train the model in Google Colab on GPU. Fine-tuning was done with the help of the Huggingface transformers API. The API is straightforward and can use the datasets library of the Huggingface ecosystem. Finally, we can export the notebook.
We transformed the notebook into a Ploomber pipeline (see the diagram below for reference).
This allowed us to break the notebook into modular pieces, run faster and
collaborate through Git. This allowed us to experiment faster since we could
use Colab’s GPUs for to compute faster, plus, the Ploomber team gave me preview
access to Ploomber Cloud, which allowed us to train many parallel experiments
to fine-tune the model.
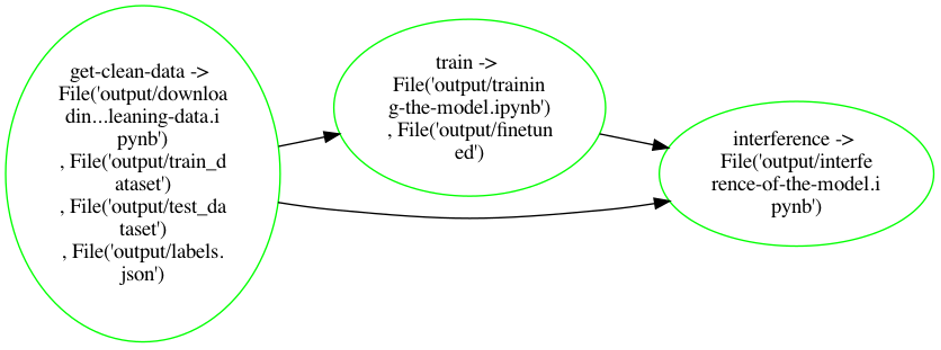
This is how the pipeline looks like and its outputs
Steps for deploying the model: 1. Build the image for the interference endpoint. We found this project to be super helpful 2. Deploy it with AWS Lambda 3. Batch-process historic articles and save them in DynamoDB
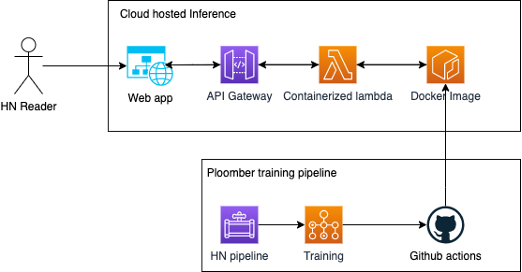
We started by getting the data from HN, cleaning and transforming it. For the topic overview page, we use DynamoDB as our backend database and query it with a lambda. Now we can process the front page and save the results in our database. Let’s go live.
For inference, we’ve used a react web application, that uses API Gateway to get the latest labels for the HN topics. We took the best-performing model we’ve got by running the pipeline. Through GitHub Actions, we’ve been pushing the latest image to the AWS ECR repository. Then we’ve configured Lambda to consume this image to serve the latest predictions.
After finding a Heroku HN api, we found this great HN clone called
reactHN by Paul Tibbetts. The next steps are:
1. Fork the frontend for our app on GitHub: reactHN
2. Add endpoint for classification (go to the app, class X and use your API endpoint)
3. Add a new API for grouped topics (deploy the CDK template)
We modified the react app and added our endpoint. The topic front page then queries our historic classified articles. We were again happy to use GitHub Pages and GitHub Actions for automatic deployments. And voila, we can read hacker news grouped by ML generated labels :)
Learnings: Language models have come a long way to enable low barrier entry to build a classifier pipeline. In the two years of this side-project, Huggingface started to dominate the space, which is nice to have a unified place for datasets, models, and probably even interference. The deployment is also a lot easier. A problem we found with using news data is the changing vocabulary and we think it would be nice to make it easier to add new tokens to language models.
Try it out here: Hackernews Classifier
Feel free to leave a comment or provide feedback if you find topic classification interesting. Thanks for reading!
If you’re looking for a better solution to orchestrate your workflows, give Ploomber a try.
Join our community, and we’ll be happy to answer all your questions.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

