


We presented a shorter version of this blog series at PyData Global 2021.
In the first two parts (part I and part II), we described a framework to increase our project robustness by incrementally adding more comprehensive testing. From smoke tests to integration tests, we transitioned from a basic project to one that ensures the generation of high-quality models.
This last part wraps up the series and has three objectives:
Let’s recap what kind of tests we introduced in the first two parts:
1. Integration (data quality) tests
1.1. Check data properties (i.e., no NULL values in column age).
1.2. Distribution changes (i.e., ensure the distribution of our target variable does not change drastically).
1.3. Model quality (i.e., detect sudden drops/lifts in model’s performance).
2. Unit tests
2.1 Check consistency between training and serving pipeline (aka training-serving skew test).
2.2 Check data transformations correctness (test a data transformation’s output given some representative inputs).
2.3. Check the compatibility of a model file and inference pipeline.
We want our tests to fail fast, so we’ll run the unit tests first (training-serving skew and data transformations). If they pass, we proceed to run the pipeline with a data sample (integration tests); if it succeeds, we use the generated model file and check compatibility with the inference pipeline; we describe the complete process in the following diagram:
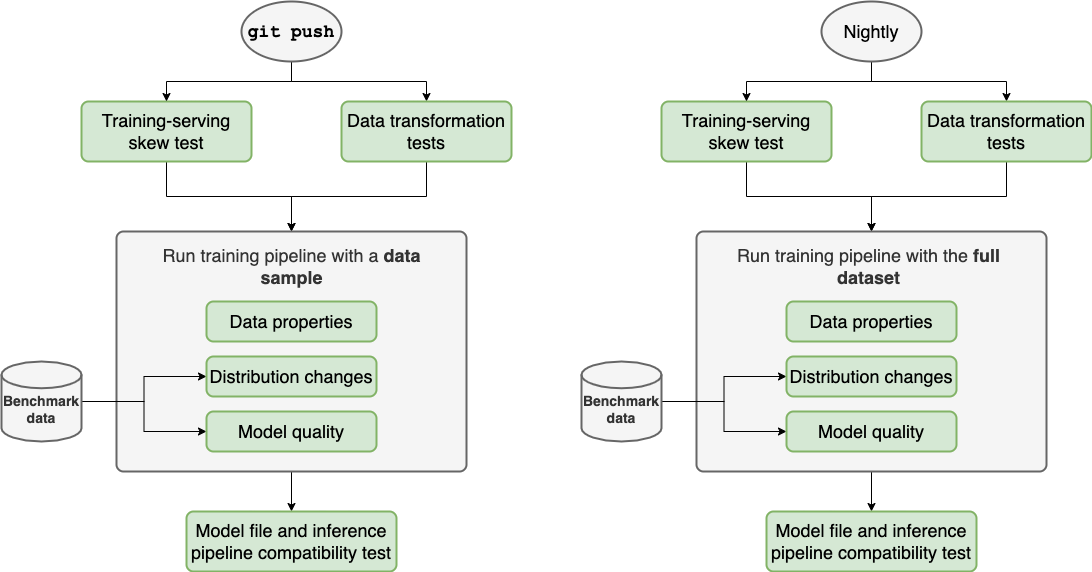
Note that we recommend repeating the same process with the entire dataset nightly; however, the shorter the schedule interval, the better.
One crucial difference is that integration tests depend on the training data since they evaluate its quality. In contrast, unit tests do not since they assess the correctness of our code. Thus, we can test them with a few representative examples.
This dependence on the training data has implications for defining our testing strategy. Ideally, we want our integration tests to check our entire dataset. However, this is unfeasible, so we resort to random sampling (say 1%) to quickly test data quality. While effective, this random sampling approach is just an approximation of what we’d get if we tested on the entire dataset.
On the other hand, since unit tests do not depend on our training data, we can use a few representative inputs for testing; hence, the expected runtime should be short (no more than a few minutes). Furthermore, since unit tests run fast, they should be the first thing you test, so you don’t have to run the expensive integration tests if something is wrong with the unit tests.
So, overall, we should aim for our testing suite (integration tests with a random sample and unit tests) to have no more than 20 minutes of runtime.
Let’s now describe a strategy to determine what test to implement whenever we encounter an error.
Our strategy depends on the specific situation; let’s look at each of them:
Suppose data properties fail (i.e., a column suddenly has NULL values). In that case, there are two options: update your code to filter out the offending records (this will cause the test to pass), or relax the tests (e.g., delete the test to allow NULL values, or allow up to certain a percentage). The decision will depend on your use case: perhaps you decide to do data imputation, so you decide to allow some NULL values; on the other hand, you may determine that you cannot impute data, in such case, update the code to filter out the offending records.
If a data distribution changes, you must determine if the difference is due to an actual change in the data generation process or if it’s due to some data ingestion or data transformation error. For example, say you detect a difference in the age column: the median age was 25, now 40. It could be that the target population aged, and you now have to update your reference values. On the other hand, it could be that an upstream data transformation changed, and it is passing records that you shouldn’t use; if that’s the case, you may want to review that upstream process to filter out the new records that altered the data distribution.
Once you have a first model in production, improvements usually come in small increments. So whenever there is a significant drop or lift in model quality, it’s important to investigate it. As mentioned in the second part of this series, you need a benchmark model to evaluate the current model’s quality; this will typically be the current model in production.
Sudden decreases in performance mean some integration tests are missing (because integration tests should detect low-quality data before entering the model training task). In comparison, sudden significant lifts in performance may indicate problems such as leakage.
If your model performance gets much worse than the benchmark, compare the code used to train the current and the benchmark to determine what changed (e.g., removed a feature, changed hyperparameters). On the other hand, if the model’s performance gets a lot better than the benchmark, review the code changes and ensure that there aren’t any problems such as leakage. If you don’t find any issues, congratulations, you just made your model better! Accept the changes and update the benchmark metrics.
If you find a problem with the training pipeline after the investigation, translate that into an integration test. For example, if your model got worse because you trained it on a column with NULL values, then add an integration test for that. Once you add the test, fix the pipeline, and ensure that the changes fix the performance issues.
Note that we recommended testing your pipeline on each git push with a data sample to make it practical; however, this implies that the output training set will be smaller, making it challenging to evaluate performance. If possible, assess the performance of a model trained on a data sample against a benchmark model trained on the same sample size. However, if it’s challenging to do so (i.e., performance varies too much across experiments), you may decide only to run model quality tests nightly.
If your training-serving skew test fails, compare the outputs of your training and serving pipeline until you find the first step where results differ. Once you spot the problem, fix it and keep running the test until it passes for all sample inputs. This step-by-step debugging process is why we need to build modular pipelines: if we write our entire project in a single notebook/script, it will be hard to spot these issues.
For example, the following diagram shows pipelines that process inputs differently (they generate a different feature vector). So once you detect that problem, check the outputs backward until you find the difference; in this case, the problem is the Process input A step, since it produces a different result at training (2) and serving time (10).
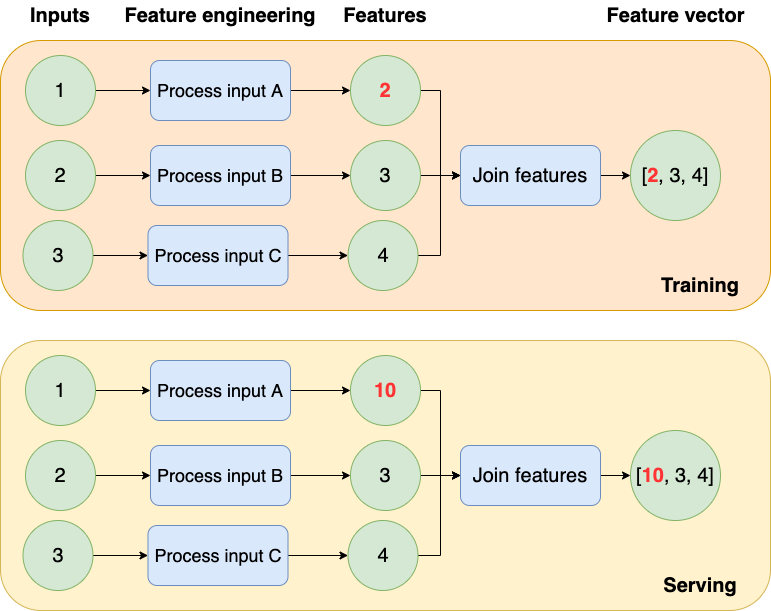
If a data transformation (usually a single function) test fails, it must be due to a change in the transformation’s source code. Sometimes, we make mistakes when optimizing a transformation (e.g., to be more memory-efficient), and unit tests allow us to detect them. Still, other times, we may change the transformation’s behavior. Hence the input samples in the unit test will no longer be representative. In any case, make sure you determine which scenario applies to you and either fix the source code or change the sample inputs.
Bear in mind that your unit tests should be in constant evolution. Therefore, whenever you find an edge case, ensure you add a new input test case: the unit tests should cover all representative input cases that your transformation should consider.
Your inference pipeline captures the pre-processing logic needed to transform raw data into a feature vector that the model uses as input; these two elements may get out of sync. For example, you may have a model file trained on features [A, B, C] (in that order). Still, if you recently updated your inference logic, it may generate features in a different order (say, [C, B, A]), which will break your inference process. You can usually fix an incompatibility between the model file and the inference pipeline by generating a model file with the same git commit; however, it’s essential to run this test to ensure you do not deploy incompatible artifacts.
Unit tests should run fast (a few minutes) since they run with a few representative inputs. However, it is challenging to run integration tests quickly since they depend on the training data. To help with this, we run the training pipeline with a random sample; however, this may not detect issues present in the entire dataset.
For example, if we’re testing data properties such as no NULL values, the test results may change if we test with 1% of our data vs. the entire dataset. Distributions are also affected; testing with a smaller sample increases the change of a false positive (detecting a difference when there isn’t one). Furthermore, evaluating model performance with a sample of the data will almost surely give a model with worse metrics.
To balance runtime vs. testing robustness, I recommend the following: run integration tests with the most extensive data sample that still gives you a reasonable test runtime (I’d say no more than 20 minutes). On top of that, schedule a run with the complete dataset as often as you can. For example, if running the training pipeline end-to-end with the entire dataset takes 2-3 hours, you may run it nightly.
On top of that, you can leverage incremental builds: say you already computed and stored all results from your pipeline; if you only change the last step, you don’t need to rerun everything from scratch. So instead, only execute steps whose source code has changed since the previous run. Unfortunately, not all pipeline frameworks support this (but Ploomber does!). Nevertheless, incremental builds hugely speed up development and testing speed.
In some cases, training procedures may take a lot to finish (e.g., deep neural networks). If that’s the case, you may use a surrogate model for testing purposes (e.g., if your neural network has ten hidden layers, use a surrogate model with 3 of them). If there’s a problem with your training data, there’s a good chance that the surrogate model will also exhibit lower performance.
One of the biggest challenges I found when testing my ML projects was the lack of appropriate tooling. We designed Ploomber to support this testing workflow (so we highly encourage you to give it a try!), but here is some general advice when choosing a framework.
Often, frameworks designed to run distributively (e.g., on Kubernetes) do not have an easy way to execute pipelines in a single-node environment; depending on external infrastructure complicates testing. So prefer frameworks that allow you to run your code in single-node environments. Testing should be as spinning up a machine and calling:
# install dependencies
pip install -r requirements.txt
# run tests
pytest
Testing requires some configuration and preparation; for example, you may need to create a temporary directory to run your pipeline with a sample. Testing frameworks such as pytest allow you to do that. The typical structure of a test goes like this:
def test_something():
# prepare environment
# run code
# test output
To use a testing framework, you should be able to import and run your pipeline using Python, so ensure that the library you’ll use allows you to do that. A test may look like this:
import my_pipeline
from model_evaluation import compare_to_benchmark
def test_train_model():
create_tmp_directory()
outputs = my_pipeline.train_model(sample=True)
assert compare_to_benchmark(outputs['model_quality'])
Your training pipeline must expose parameters to allow you to run them with different configurations. When testing, you want to run it with a sample of the data and store any results in a separate folder to prevent overwriting your results, so ensure the framework you use allows you to parametrize your pipeline:
import my_project
# gets data, cleans it, generates features and stores model in /output/full/
my_project.train_model(sample=False)
# gets data, cleans it, generates features and stores model in /output/sampled/
my_project.train_model(sample=True)
Testing ML pipelines is a difficult endeavor: large datasets and long training cycles posit significant challenges to ensure tests run in a reasonable amount of time. However, simple testing strategies such as smoke testing and testing with a small random sample pay off, so ensure you implement those basic strategies and move to more advanced ones as your project matures.
A fundamental requirement to develop testable projects is to modularize your work. Monolith notebooks that contain the entire data processing logic in a single file are a nightmare to test and maintain, so ensure you use a framework that allows you to break down logic in small steps so you can test each in isolation.
My experience as a Data Scientist inspired these guidelines; however, this is an evolving field, so if you have any questions or want to chat about all things ML testing, join our community!
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

