



Outlines is a Python library designed to simplify the usage of Large Language Models (LLMs) with structured generation. Structured generation is the process of taking the output of an LLM and transforming it into a more suitable format. This is very useful when you are using LLMs to generate any form of structured data. Here are a few reasons why you might want to use it:
Now let’s discuss the key features provided by Outlines:
To find out more about the features of Outlines, check out their documentation.
Outlines can be installed by running the following command:
pip install outlines
Outlines can also be deployed as an LLM service with vLLM and a FastAPI server. vLLM isn’t installed by default, so you’ll need to install it separately:
pip install outlines[serve]
Keep in mind that vLLM requires Linux and Python >=3.8. Furthermore, it requires a GPU with compute capability >=7.0 (e.g., V100, T4, RTX20xx, A100, L4, H100).
Finally, vLLM is compiled with CUDA 12.1, so you need to ensure that your machine is running such CUDA version. To check it, run:
nvcc --version
If you’re not running CUDA 12.1 you can either install a version of vLLM compiled with the CUDA version you’re running (see the installation instructions to learn more), or install CUDA 12.1.
For step-by-step instructions on installing vLLM, you can explore this blog post for a detailed guide.
Once vLLM is installed you can start the server by running:
python -m outlines.serve.serve --model=<model_name>
Alternatively, you can install and run the server with Outlines' official Docker image using the command:
docker run -p 8000:8000 outlinesdev/outlines --model=<model_name>
Let’s see an example of starting the server using the google/gemma-2b model. Note that some models, such as this require you to accept their license. Hence, you need to create a HuggingFace account, accept the model’s license, and generate a token.
For example, when opening google/gemma-2b on HuggingFace
(you need to be logged in), you’ll see this:
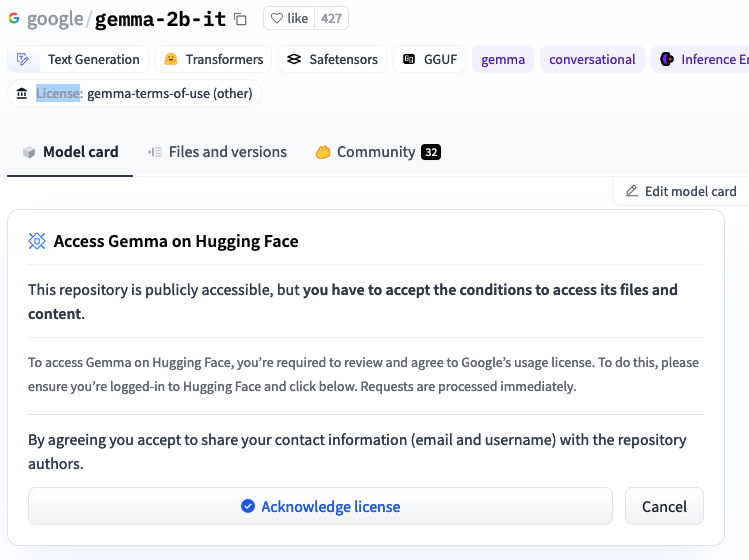
Once you accept the license, head over to the tokens section, and grab a token, then, before starting vLLM, set the token as follows:
export HF_TOKEN=YOURTOKEN
Once the token is set, you can start the server.
python -m "outlines.serve.serve --model google/gemma-2b-it
Once the server is up and running, you’re ready to send requests. You can query the model by providing a prompt along with either a JSON Schema specification or a Regex pattern.
Let’s look at an example using the JSON Schema specification. We’ll use the google/gemma-2b model and the Python requests library:
import json
import requests
# change for your host
OUTLINES_HOST = "https://odd-disk-6303.ploomber.app"
url = f"{OUTLINES_HOST}/generate"
schema = {
"type": "object",
"properties": {
"a": {
"type": "integer"
},
"b": {
"type": "integer"
}
},
"required": ["a", "b"]
}
headers = {"Content-Type": "application/json"}
data = {
"prompt": "Return two integers named a and b respectively. a is odd and b even.",
"schema": schema
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["text"])
The output generated was as follows:
['Return two integers named a and b respectively. a is odd and b even.{"a": 1, "b": 2}']
To avoid the hassle of configuration, you can deploy vLLM on Ploomber Cloud with just one click.
Start by creating an account on Ploomber Cloud.
For a sample application, refer to the example repository. The deployment steps are similar to those outlined in the vLLM deployment guide.
Generate a zip file from the Dockerfile and the dependencies file. Login to your Ploomber Cloud account and follow the steps here
to deploy it as a Docker application.
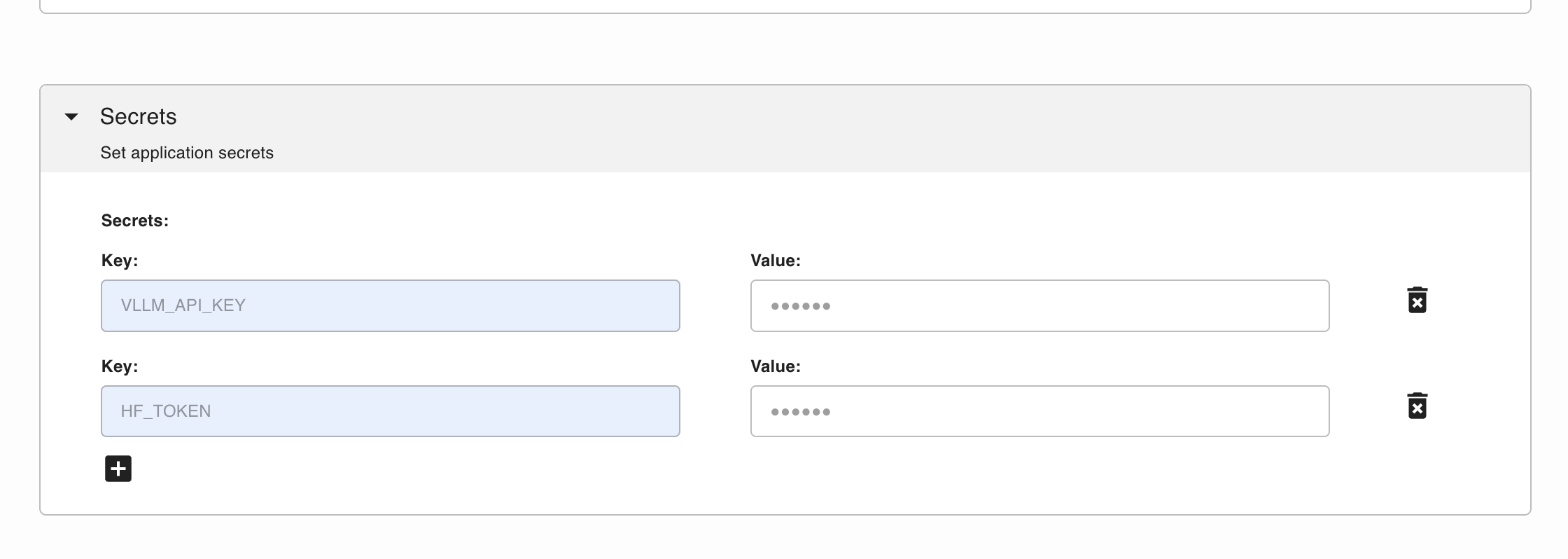
If your model requires license acceptance, you will need to provide a valid HF_TOKEN in the Secrets section for vLLM to download the weights.
Additionally, you can protect your server by setting the VLLM_API_KEY secret, which you can generate with the following command:
python -c 'import secrets; print(secrets.token_urlsafe())'
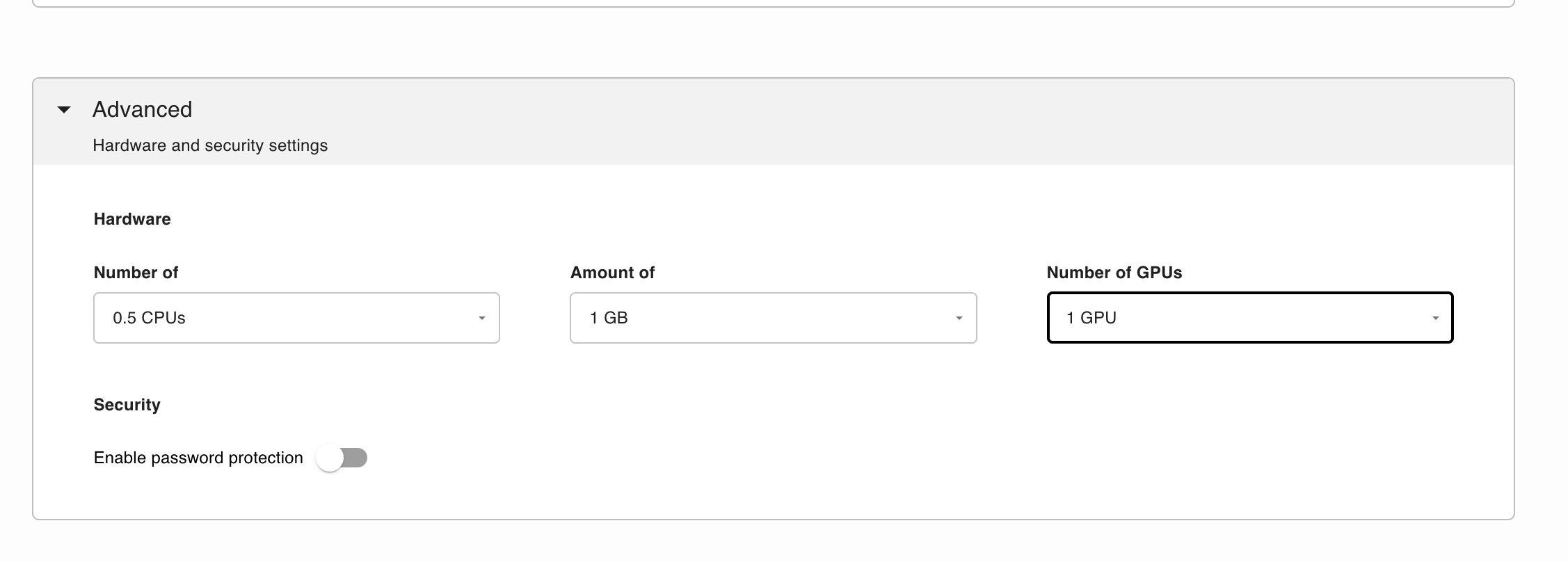
You also need to select GPU for the deployment to work:
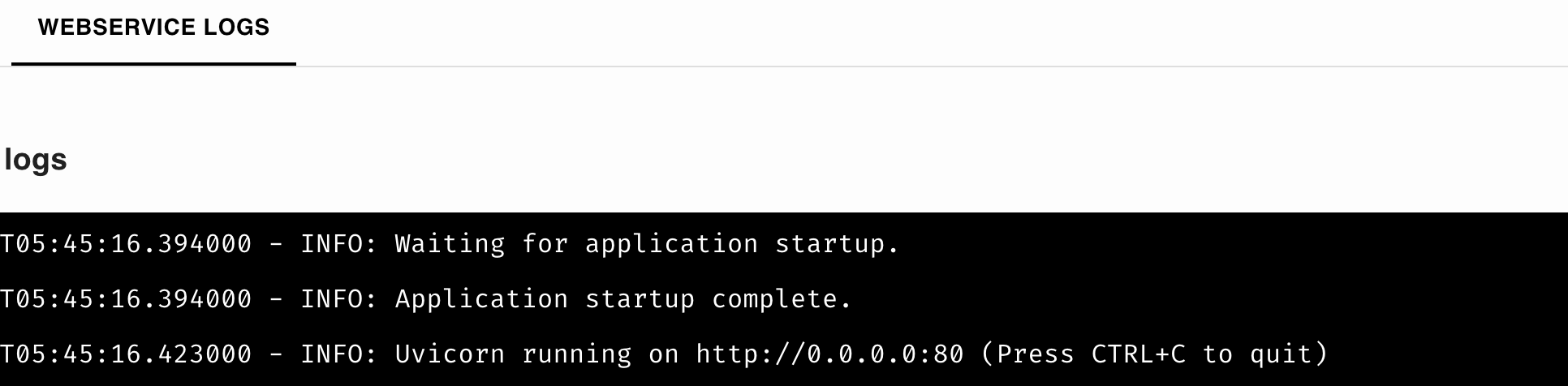
Once the deployment is complete, you should see the below logs:
After the deployment, you have the option to either send cURL requests or write a Python script using the requests library to interact with the model.
Refer to the Serve with vLLM guide to learn more.
Let’s quickly recap the key points discussed in the post:
Outlines is a powerful Python library that enables structured output generation from LLMs.vLLM, and the model can be accessed through cURL requests or the Python requests library.Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

