



A PDF (Portable Document Format) is a widely used file format for documents that preserves their original appearance and formatting across different devices and platforms.
A native PDF is a PDF of a document that was “born digital” because the PDF was created from an electronic version of a document, rather than from print.
A scanned PDF, on the other hand, is generated by scanning documents and then saving them in PDF format. Text in scanned PDFs is not searchable, as it is just a collection of images.
Extracting text from PDFs is important for
A text extraction software extracts text from native PDF files by utilizing information such as fonts, encodings, typical character distances, etc. However, to extract text from scanned PDFs, we need tools that provide OCR (Optical Character Recognition) technology.
In this blog post, our primary focus will be on exploring OCR techniques for extracting text from PDF files.
There are broadly three types of OCR techniques for extracting text from scanned PDFs:
Let’s try each of these techniques on this sample scanned PDF.
In this section, we’ll look at 2 ways of extracting text from PDF files by first converting them to images.
The pdf2image library is a Python package that converts PDF documents into PIL Image objects. It leverages popular external tools like Poppler or Ghostscript to perform the conversion.
Python-tesseract is an optical character recognition (OCR) tool for Python. It is a wrapper for Google’s Tesseract-OCR Engine. Tesseract is an open-source OCR Engine that extracts printed or written text from images. It was originally developed by Hewlett-Packard, and development was later taken over by Google.
Here are some advantages of using Tesseract:
First, we need to install Tesseract.
Now install the Python packages:
%pip install pdf2image pytesseract --quiet
Next, we’ll first convert the PDF pages to PIL objects and then extract text from these objects using pytesseract’s image_to_string method:
import pytesseract
from pdf2image import convert_from_path
# convert to image using resolution 600 dpi
pages = convert_from_path("scanned.pdf", 600)
# extract text
text_data = ''
for page in pages:
text = pytesseract.image_to_string(page)
text_data += text + '\n'
print(text_data)
PFU Business report
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
(The main product and service at this season]
@From the product headquarters
In the image business, the new model turning on of the A3 high-speed, a _bad
two sided color scanner that achieved a high-speed reading aimed at. —
wroom was established in United States, Europe, and Asia/Oceania.
Image business
1) Scanner class
A3 high-speed, two sided color scanner "fi-5900C" that 100 high-n
function to enable industry-leading was installed was announced in
ScanSnap gotten popular because of an office and individual use.
2) DLM solution scanner ~ |
The DLM solution that used received the rise of the concern to efficient Satisfaction rating to new product
management and internal management of the corporate private circum-
stances report in recent years and attracted attention. The function of software that the inspection of data is possible by
the sense that turns over the file is strengthened, and easiness to use has been improved.
{approach on business risk]
@In-house activity
The attestation intended for each office in Shinbashi, Kansai, and Tokai was acquired in environment ISO in February,
2006. In addition, it participates in the minus 6% that is a national movement of the global warming prevention, and
"Culbiz" is done. The scandal of the enterprise has frequently generated is received, concern is sent to the system mainte-
nance including the observance of the law in recent years.
@Enhancement of system of management ‘s
The committee that aimed at the decrease of a variety of business 80
risks in an individual business talk was newly established. Moreover, 70
the recognition of "Privacy mark" is received to manage customer and si
employee's individual information appropriately in 2001, and the activ- ? bP ae
ity based on the protection of individual information policy is continued. 30
lt is .bAsia/Oceania in globalln addition, our technology, commodity 20
power, and correspondence power were evaluating acquired. 10 ti
0
1998 1999 2000 2001 2002 2003 2004
Satisfaction rating to new product
EasyOCR is another open-source library that supports 80+ languages. Let’s look at some advantages of EasyOCR:
First, install the required packages:
%pip install pymupdf easyocr --quiet
Next, convert the PDF pages into png files using PyMuPDF:
import fitz
pdffile = "scanned.pdf"
doc = fitz.open(pdffile)
zoom = 4
mat = fitz.Matrix(zoom, zoom)
count = 0
# Count variable is to get the number of pages in the pdf
for p in doc:
count += 1
for i in range(count):
val = f"image_{i+1}.png"
page = doc.load_page(i)
pix = page.get_pixmap(matrix=mat)
pix.save(val)
doc.close()
Since the PDF has just one page we’ll apply EasyOCR on image_1.png:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext("image_1.png", detail=0)
result
['PFU Business report',
'No.068',
"New customer's development",
'and increasing the sale of product',
'My country economy at this season keeps escaping from Odoba of business though holds a crude oil',
'high so on unstable element that continues still, and recovering gradually and well,',
'In the IT industry, there is an influence such as competing intensification in narrowing investment field.',
'[The main product and service at this season]',
'From the product headquarters',
'In the image business; the new model turning on of the A3 high-speed,',
'usually',
'bad',
'two sided color scanner that achieved a high-speed reading aimed at.',
'wroom was established in United States, Europe, and Asia/Oceania',
'7%',
'20%',
'very good',
'Image business',
'good',
'47%',
'1) Scanner class',
'A3 high-speed, two sided color scanner "fi-5900C"',
'that 100 high-n',
'26%',
'function to enable industry-leading was installed was announced in',
'ScanSnap gotten popular because of an office and individual use:',
'2) DLM solution scanner',
'The DLM solution that used received the rise of the concern to efficient',
'Satisfaction rating to new product',
'management and internal management of the corporate private circum-',
'stances report in recent years and attracted attention; The function of software that the inspection of data is possible by',
'the sense that turns over the file is strengthened, and easiness to use has been improved:',
'[approach on business risk]',
'In-house activity',
'The attestation intended for each office in Shinbashi, Kansai , and Tokai was acquired in environment ISO in February,',
'2006. In addition, it participates in the minus 6% that is a national movement of the global warming prevention, and',
'"Culbiz" is done. The scandal of the enterprise has frequently generated is received; concern is sent to the system mainte-',
'nance including the observance of the law in recent years:',
'100',
'Enhancement of system of management',
'90',
'The committee that aimed at the decrease of a variety of business',
'80',
'risks in an individual business talk was newly established. Moreover,',
'70',
'60',
'the',
'recognition of "Privacy mark"',
'is received to manage customer and',
'50',
"employee's individual information appropriately in 2001_",
'and the activ-',
'40',
'ity based on the protection of individual information policy is continued.',
'30',
'It is _bAsia/Oceania in globalln addition; our technology, commodity',
'20',
'power, and correspondence power were evaluating acquired:',
'10',
'0',
'1998',
'1999',
'2000',
'2001',
'2002 2003 2004',
'Satisfaction rating t0 new product',
"Bzsines$ '€pOr (",
'1td']
The results obtained from both pytesseract and EasyOCR are comparable. However, EasyOCR demonstrates an advantage over pytesseract by accurately extracting both figures and text from the pie chart.
OCRmyPDF is an open-source library that uses Tesseract internally and adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted. Let’s look at some advantages of using this package:
%pip install ocrmypdf --quiet
Next, run the command ocrmypdf to generate the modified PDF:
ocrmypdf scanned.pdf scanned_out.pdf
Now we can easily search the output document scanned_out.pdf:
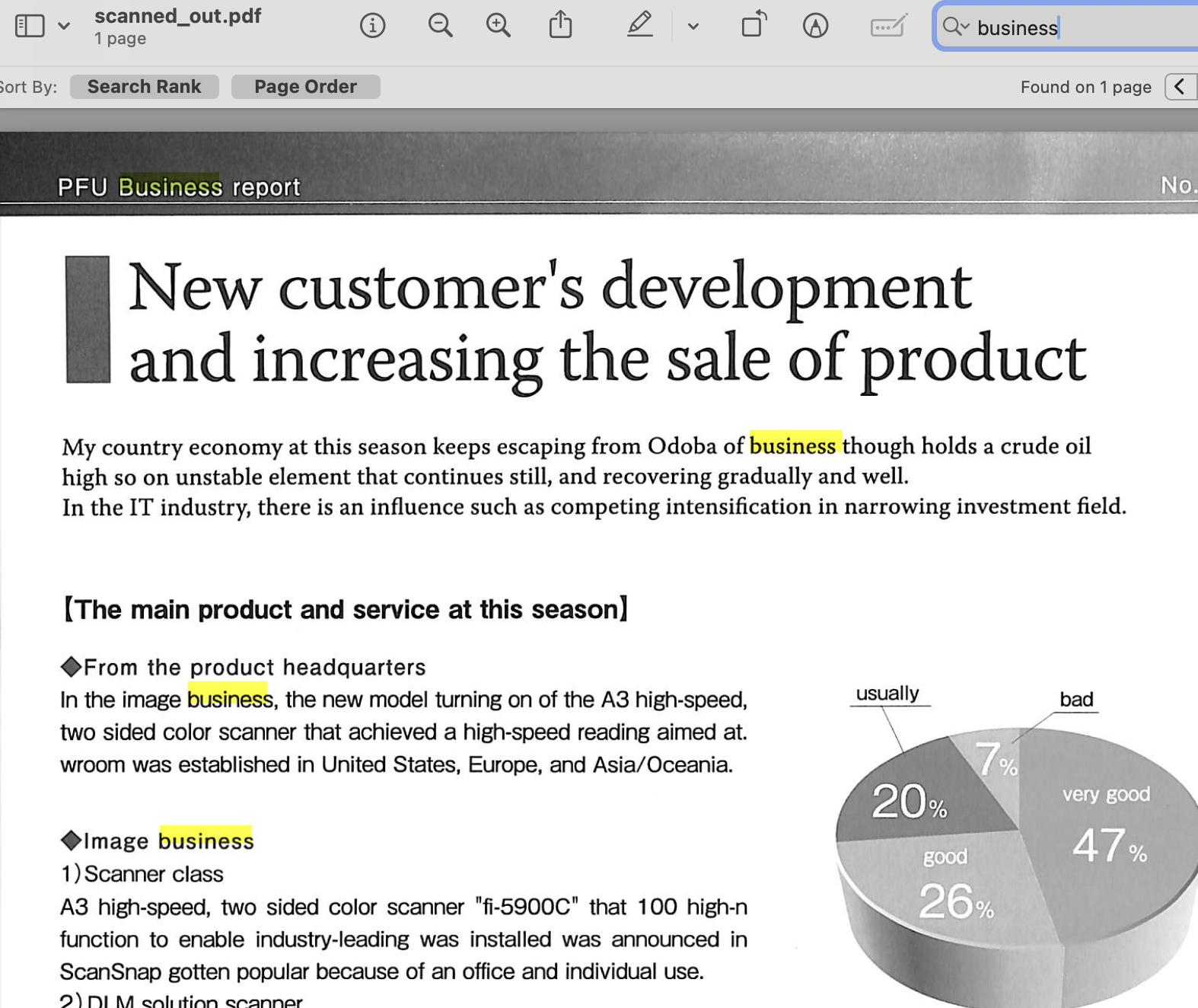
Amazon Textract is a machine learning (ML) service that automatically extracts text from scanned documents. Some of its pros include:
First, install the boto3 package:
%pip install boto3 --quiet
import boto3
client = boto3.client('textract')
response = client.detect_document_text(
Document={
'S3Object': {
'Bucket': 'pdf-ocr-files-ploomber',
'Name': 'scanned.pdf'
}
}
)
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print (item["Text"])
PFU Business report
No. 068
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
(The main product and service at this season)
From the product headquarters
In the image business, the new model turning on of the A3 high-speed,
usually
bad
two sided color scanner that achieved a high-speed reading aimed at.
wroom was established in United States, Europe, and Asia/Oceania.
7%
20%
very good
Image business
good
47%
1) Scanner class
A3 high-speed, two sided color scanner "fi-5900C" that 100 high-n
26%
function to enable industry-leading was installed was announced in
ScanSnap gotten popular because of an office and individual use.
2) DLM solution scanner
The DLM solution that used received the rise of the concern to efficient
Satisfaction rating to new product
management and internal management of the corporate private circum-
stances report in recent years and attracted attention. The function of software that the inspection of data is possible by
the sense that turns over the file is strengthened, and easiness to use has been improved.
(approach on business risk)
In-house activity
The attestation intended for each office in Shinbashi, Kansai, and Tokai was acquired in environment ISO in February,
2006. In addition, it participates in the minus 6% that is a national movement of the global warming prevention, and
"Culbiz" is done. The scandal of the enterprise has frequently generated is received, concern is sent to the system mainte-
nance including the observance of the law in recent years.
100
Enhancement of system of management
90
The committee that aimed at the decrease of a variety of business
80
risks in an individual business talk was newly established. Moreover,
70
the recognition of "Privacy mark" is received to manage customer and
60
50
employee's individual information appropriately in 2001, and the activ-
40
ity based on the protection of individual information policy is continued.
30
It is ..bAsia/Oceania in globalln addition, our technology, commodity
20
power, and correspondence power were evaluating acquired.
10
0
1998 1999 2000 2001 2002 2003 2004
Satisfaction rating to new product
1
Business report Ltd
In this section, we’ll look at the performance of OCR techniques on native PDFs and compare the result with tools like PyPDF2 which are specialised for extracting text from digitally generated PDFs. We’ll be performing text extraction on this PDF using both pytesseract and PyPDF2.
%pip install PyPDF2 --quiet
First, we’ll generate the OCR output:
import pytesseract
from pdf2image import convert_from_path
pages = convert_from_path("attention.pdf", 600)
text_data = ''
text = pytesseract.image_to_string(pages[1])
text_data += text + '\n'
print(text_data)
Recurrent models typically factor computation along the symbol positions of the input and output
sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden
states h,, as a function of the previous hidden state h;_, and the input for position t. This inherently
sequential nature precludes parallelization within training examples, which becomes critical at longer
sequence lengths, as memory constraints limit batching across examples. Recent work has achieved
significant improvements in computational efficiency through factorization tricks and conditional
computation [26], while also improving model performance in case of the latter. The fundamental
constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduc-
tion models in various tasks, allowing modeling of dependencies without regard to their distance in
the input or output sequences [2}|16]. In all but a few cases [22], however, such attention mechanisms
are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead
relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in
translation quality after being trained for as little as twelve hours on eight P100 GPUs.
2 Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU
|20], ByteNet and ConvS2S [8], all of which use convolutional neural networks as basic building
block, computing hidden representations in parallel for all input and output positions. In these models,
the number of operations required to relate signals from two arbitrary input or output positions grows
in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes
it more difficult to learn dependencies between distant positions [11]. In the Transformer this is
reduced to a constant number of operations, albeit at the cost of reduced effective resolution due
to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as
described in section[3.2]
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions
of a single sequence in order to compute a representation of the sequence. Self-attention has been
used successfully in a variety of tasks including reading comprehension, abstractive summarization,
textual entailment and learning task-independent sentence representations [41/22 {23} [19].
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-
aligned recurrence and have been shown to perform well on simple-language question answering and
language modeling tasks [28].
To the best of our knowledge, however, the Transformer is the first transduction model relying
entirely on self-attention to compute representations of its input and output without using sequence-
aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate
self-attention and discuss its advantages over models such as and [8].
3 Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure [[5} 2} [29].
Here, the encoder maps an input sequence of symbol representations (71, ...,2,,) to a sequence
of continuous representations z = (21,...,2n). Given z, the decoder then generates an output
sequence (71, .--; Ym) Of symbols one element at a time. At each step the model is auto-regressive
, consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully
connected layers for both the encoder and decoder, shown in the left and right halves of Figure[I]
respectively.
3.1 Encoder and Decoder Stacks
Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two
sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-
Next, extract text from the same file using PyPDF2:
from PyPDF2 import PdfReader
reader = PdfReader("attention.pdf")
page = reader.pages[1]
print(page.extract_text())
Recurrent models typically factor computation along the symbol positions of the input and output
sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden
statesht, as a function of the previous hidden state ht�1and the input for position t. This inherently
sequential nature precludes parallelization within training examples, which becomes critical at longer
sequence lengths, as memory constraints limit batching across examples. Recent work has achieved
significant improvements in computational efficiency through factorization tricks [ 18] and conditional
computation [ 26], while also improving model performance in case of the latter. The fundamental
constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduc-
tion models in various tasks, allowing modeling of dependencies without regard to their distance in
the input or output sequences [ 2,16]. In all but a few cases [ 22], however, such attention mechanisms
are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead
relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in
translation quality after being trained for as little as twelve hours on eight P100 GPUs.
2 Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU
[20], ByteNet [ 15] and ConvS2S [ 8], all of which use convolutional neural networks as basic building
block, computing hidden representations in parallel for all input and output positions. In these models,
the number of operations required to relate signals from two arbitrary input or output positions grows
in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes
it more difficult to learn dependencies between distant positions [ 11]. In the Transformer this is
reduced to a constant number of operations, albeit at the cost of reduced effective resolution due
to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as
described in section 3.2.
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions
of a single sequence in order to compute a representation of the sequence. Self-attention has been
used successfully in a variety of tasks including reading comprehension, abstractive summarization,
textual entailment and learning task-independent sentence representations [4, 22, 23, 19].
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-
aligned recurrence and have been shown to perform well on simple-language question answering and
language modeling tasks [28].
To the best of our knowledge, however, the Transformer is the first transduction model relying
entirely on self-attention to compute representations of its input and output without using sequence-
aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate
self-attention and discuss its advantages over models such as [14, 15] and [8].
3 Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure [ 5,2,29].
Here, the encoder maps an input sequence of symbol representations (x1;:::;x n)to a sequence
of continuous representations z= (z1;:::;z n). Given z, the decoder then generates an output
sequence (y1;:::;y m)of symbols one element at a time. At each step the model is auto-regressive
[9], consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully
connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1,
respectively.
3.1 Encoder and Decoder Stacks
Encoder: The encoder is composed of a stack of N= 6 identical layers. Each layer has two
sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-
2
Let’s see some differences in the outputs. The left output is of pytesseract and the right one is of PyPDF2:

The OCR confuses characters like ht which PyPDF2 correctly extracts. The OCR also misses out or incorrectly converts some numbers within square brackets.
You can also refer to the PyPDF2 documentation for more details on why specialised tools should be preferred over OCR techniques for digital PDF files.
Here are some parameters to consider when comparing the discussed libraries:
| pytesseract | easyOCR | OCRmyPDF | AWS Textract | |
|---|---|---|---|---|
| Language support | 100+ languages | 80+ languages | 100+ languages | English, Spanish, German, Italian, French, and Portuguese |
| Pricing | Free to use, open-source | Free to use, open-source | Free to use, open-source | Paid |
| Techniques | statistical methods + Neural Networks | CNNs + LSTMs | statistical methods + Neural Networks | ML based |
| Table extraction | Unsupported | Unsupported | Less accurate | Supported |
PyMuPDF or PyPDF2 can efficiently extract text without the need for OCR.AWS Textract emerges as a powerful choice if the requirement is scalable OCR workflows. Its managed service architecture, combined with pre-trained and customizable features, makes it suitable for large-scale OCR tasks.EasyOCR stands out. Its user-friendly API, built on deep learning frameworks like PyTorch, ensures fast and efficient OCR with support for numerous languages.pytesseract is a great option.AWS Textract provides specialized functionalities.In this blog, we delved into various OCR techniques for extracting text from scanned PDF documents. We explored the capabilities of popular open-source libraries such as pytesseract, OCRmyPDF, and EasyOCR, each offering extensive language support and backed by vibrant open-source communities of contributors and developers.
Additionally, we discussed the advantages of AWS Textract, highlighting its suitability for building scalable OCR workflows. With specialized features like table extraction and key-value pair extraction, AWS Textract excels in handling diverse document processing tasks, making it a preferred choice for advanced applications.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

