



In this blog, we delve into “Prompt Design and Engineering: Introduction and Advanced Methods” by Xavier Amatriain, a comprehensive examination of prompt engineering for LLMs like GPT-3 and DALL-E. We aim to offer a grounded exploration of the paper’s insights on overcoming LLM limitations, such as memory constraints and the propensity for outdated information. Through code examples and API integration with LLM providers, we will apply the techniques explored in this paper, including Chain of Thought and Retrieval Augmented Generation, showcasing practical applications in AI development with a focus on professional implementation.
Prompt engineering is the process of designing and refining prompts to guide language model outputs. It is a crucial aspect of leveraging large language models (LLMs) like GPT-3 and DALL-E, which are known for their ability to respond to human-like text. However, these models can produce outputs that are inaccurate, biased, or irrelevant if not guided by well-crafted prompts. Prompt engineering involves creating instructions that effectively steer the model’s outputs toward the desired results, ensuring that the generated text aligns with the user’s intentions and requirements.
Prompt engineering is essential for harnessing the full potential of LLMs while mitigating their limitations. By providing clear and precise prompts, developers can guide the model’s responses, ensuring that the generated text is accurate, relevant, and aligned with the user’s needs. This is particularly important when using LLMs for specific tasks, such as content generation, question answering, or language translation. Without well-designed prompts, the model’s outputs may be inconsistent, biased, or uninformative, leading to suboptimal results and user dissatisfaction.
The paper “Prompt Design and Engineering” by Xavier Amatriain explores several key techniques in prompt engineering. These techniques are designed to address common challenges associated with LLMs and provide practical strategies for improving prompt design and engineering. We will explore through code examples how these techniques can be implemented using LLM through APIs.
Below, we provide an overview of each technique explored in the paper, along with its use case:
| Technique | Use Case |
|---|---|
| Chain of Thought (CoT) | Best for complex reasoning tasks where breaking down the problem into intermediate steps can guide the model to a logical conclusion. |
| Tree of Thought (ToT) | Useful for problems requiring branching logic or exploring multiple pathways to find solutions. |
| Tools Connectors and Skills | Ideal when tasks require external tools or databases, enhancing the model’s capability by integrating specialized knowledge or functionalities. |
| Automatic Multi-step Reasoning and Tool-use (ART) | Suited for tasks that benefit from automatic reasoning and the use of external tools or databases in a multi-step process. |
| Self-Consistency | Applied to improve the reliability of answers by having the model generate multiple answers and select the most consistent one. |
| Reflection | Useful for tasks that require the model to evaluate or improve its own responses by considering its answers critically. |
| Expert Prompting | Best for domain-specific tasks where leveraging specialized knowledge can lead to more accurate and nuanced responses. |
| Chains and Rails | Effective for guiding the model through a series of logical steps or ensuring it stays on track within a specific problem-solving framework. |
| Automatic Prompt Engineering (APE) | Ideal for optimizing prompt creation process efficiency and effectiveness, especially in scalable or dynamic application contexts. |
| Retrieval Augmented Generation (RAG) | Enhances model responses with external knowledge, best for when up-to-date or detailed domain-specific information is critical. |
We can interact with LLMs through a user interface, such as OpenAI’s Chat GPT. We can also interact with an LLM through code by making API calls to an LLM hosted by a provider. Providers that enable us to access LLMs programmatically include:
To execute LLMs locally, we can use Ollama.
Choosing between an LLM provider and a set of techniques that best align with our use case is crucial. One of the challenges in prompt engineering is to understand the capabilities and limitations of each LLM provider and how to leverage them effectively. We will explore how to use Haystack 2.0 to orchestrate LLM providers programmatically and apply the techniques from the paper to guide the model’s outputs effectively.
In this first scenario, we will use the OpenAI API to interact with GPT-3. We will explore how to apply introductory techniques Chain of Thought and Tree of Thought from the paper to guide the model’s outputs effectively. We will use the openai library to make API calls to GPT-3 and demonstrate how to apply the techniques from the paper to guide the model’s outputs effectively.
To get started, we need to install the library and its dependencies. We can do this with pip by running the following command in our terminal or command prompt:
pip install openai python-dotenv
Ensure you create an OpenAI API key before proceeding. You can create an API key by signing up for an account on the OpenAI platform and following the instructions provided. Once you have your API key, you can store it in a .env file in the root directory of your project. The .env file should contain the following line:
OPENAI_API_KEY=your-api-key
Once this is complete, we can get started with the code examples and API integration.
We can use the OpenAI API to interact with GPT-3 programmatically. To do this, we need to set up an API key and use the openai library to make requests to the GPT-3 model. Below, we provide an example of how to build a prompt for GPT-3 using Python.
Within the context of interacting with OpenAI’s systems, particularly in scenarios involving AI models like ChatGPT, three key level instructions are often referenced: system, assistant, and user. Each of these roles has a distinct function and purpose in the interaction process:
System: This level instruction is used to guide your model’s behavior throughout the conversation.
Assistant: The assistant is the AI model that generates responses based on the inputs it receives.
User: The user is the individual or entity that interacts with the assistant through the system. Users can be anyone from individual people seeking information, entertainment, or help with a task, to organizations and developers integrating OpenAI’s models into their applications for various purposes.
The function ask_gpt_35_turbo_cot takes a question as input along with an OpenAI client and generates a prompt for GPT-3 using the Chain of Thought (CoT) technique. The function then makes a request to the GPT-3 model and returns the response.
We can specify the roles as follows:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": instruction},
{"role": "user", "content": question},
{"role": "assistant", "content": prompt},
]
)
Let’s take a look at a complete workflow:
from openai import OpenAI
import os
from dotenv import load_dotenv
def ask_gpt_35_turbo_cot(question, client):
prompt = f"Question: {question}\nAnswer: Let’s think step by step."
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Your task is to answer questions in a systematic manner.\
Think step by step and provide insight into the steps you take to answer the question."},
{"role": "user", "content": question},
{"role": "assistant", "content": prompt},
{"role": "user", "content": question},
{"role": "assistant", "content": prompt},
]
)
# Extracting the text from the response
answer = response.choices[0].message.content
if "insufficient information" not in answer.lower():
answer = f"{answer}"
return answer
# Load the OpenAI API key from a .env file
load_dotenv()
openai_key = os.getenv("OPENAI_KEY")
# Initialize the OpenAI client
client = OpenAI(api_key=openai_key)
# Example usage
question = "How much is 2 plus 2"
answer = ask_gpt_35_turbo(question, client)
print(answer)
Here is the LLM’s response:
"""
Step 1: Start with the first number, which is 2.
Step 2: Add the second number, which is also 2.
Step 3: Combine the two numbers together by adding them.
Step 4: The result is 4.
"""
The workflow above allows us to direct the LLM’s responses using the Chain of Thought (CoT) technique. By providing a prompt that guides the model to think step by step, we can ensure that the generated response follows a logical sequence of reasoning. This is particularly useful for complex reasoning tasks where breaking down the problem into intermediate steps can guide the model to a logical conclusion.
Next, we will take a look at Tree of Thought (ToT) and how it can be applied to guide the model’s outputs effectively.
The Tree of Thought (ToT) approach is designed for problems requiring multiple pathways or branching logic to explore various solutions. It’s particularly effective in scenarios where there isn’t a single linear path to the answer, allowing the model to consider different perspectives or solution strategies before reaching a conclusion.
Here’s an example prompt template for the Tree of Thought technique:
def ask_gpt_35_turbo_tot(question, client):
# Updated prompt format with multiple paths consideration
prompt = f"""Question: {question}
Answer: Let’s consider different paths.
First, we consider [path A] which could lead us to [outcome A],
because [reasoning for path A].
Alternatively, [path B] might result in [outcome B]
due to [reasoning for path B].
Considering all angles, the most plausible solution
is [chosen outcome] because [final reasoning].
If none of the paths provide sufficient information,
we might need more data to decide."""
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Consider different paths and reason through them."},
{"role": "user", "content": question},
{"role": "assistant", "content": prompt},
]
)
# Extracting the text from the response
answer = response.choices[0].message.content
return answer
question = "Should a company invest in renewable energy or traditional fossil fuels?"
answer = ask_gpt_35_turbo_tot(question, client)
print(answer)
This yields a data structure with the following response (the response is verbose, you can display it below)
"""
Path A: Investing in Renewable Energy
Outcome A: The company invests in renewable energy sources, such as solar or wind power.
Reasoning for Path A:
1. Environmental Concerns: Investing in renewable energy aligns with global efforts to
combat climate change and reduce greenhouse gas emissions. It demonstrates corporate
social responsibility and may improve the company's public image.
2. Long-Term Cost Savings: Renewable energy sources, once installed, typically
have lower operating costs and provide stable long-term energy prices.
This can result in cost savings for the company in the long run.
3. Government Incentives: Many governments offer incentives, such as tax credits or
subsidies, for investing in renewable energy, which can help offset initial investment costs.
4. Future Market Potential: The renewable energy market is continuously growing,
presenting opportunities for expanding the company's portfolio and attracting
environmentally conscious customers.
Path B: Investing in Traditional Fossil Fuels
Outcome B: The company invests in traditional fossil fuel sources,
such as coal, oil, or natural gas.
Reasoning for Path B:
1. Reliability: Fossil fuels have been the primary source of energy for many
years and are well-established. Their infrastructure and distribution systems
are highly developed and reliable.
2. Cost Competitiveness: At present, some fossil fuel options, such as coal or
natural gas, can be cheaper than renewable energy sources, making them
economically appealing for some companies.
3. Energy Intensity: Certain industries, like heavy manufacturing or aviation,
rely heavily on fossil fuels due to their high energy density and availability.
For such industries, finding adequate alternatives may be challenging.
Chosen Outcome:
Based on the reasoning presented above, the most plausible solution is to invest
in renewable energy (Outcome A). This decision is driven by environmental concerns,
long-term cost savings, government incentives, and the potential for growth
in the renewable energy market.
However, it is essential to note that each company's circumstances might differ,
and a thorough analysis of their specific needs, costs, and future market trends
is necessary to make an informed decision.
If there is insufficient information to choose a path, further data gathering,
such as evaluating the company's financial capabilities, exploring available
renewable energy options, and assessing the potential impact on the
company's operations, would be required.
"""
In this section, we explored how to use the Chain of Thought (CoT) and Tree of Thought (ToT) techniques to guide the model’s outputs effectively. By providing a prompt that considers breaking down the response into steps, access to different paths and reasons through them, we can guide the model to explore multiple perspectives and solution strategies before reaching a conclusion. This approach is particularly useful for problems requiring branching logic or exploring multiple pathways to find solutions.
In the next section we will explore how to incorporate outside tools and combine them with these two techniques through the use of an LLM orchestration tool.
In this example, we will use Haystack 2.0 to orchestrate LLMs from different providers and apply the techniques from the paper to guide the model’s outputs effectively. Haystack 2.0 is an open-source framework that allows us to build end-to-end pipelines for working with large language models (LLMs) and other natural language processing (NLP) tasks. It provides a modular and extensible architecture for integrating LLMs, data retrieval, and other components to create powerful NLP workflows. It is useful to orchestrate LLMs from different providers and apply the techniques from the paper to guide the model’s outputs effectively.
![]()
Haystack 2.0 supports a wide variety of integrations categorized as follows:
By leveraging these integrations, we can build powerful NLP pipelines that incorporate external tools, databases, and LLMs to guide the model’s outputs effectively.
To get started, we need to install Haystack 2.0 and its dependencies. We can do this with pip by running the following command in our terminal or command prompt:
pip install haystack-ai
Once this is complete, we can get started with the code examples and API integration.
Let’s explore how to use Haystack 2.0 to orchestrate LLMs from different providers and apply the techniques from the paper to guide the model’s outputs effectively. We will turn our attention to Tools Connectors and Skills and Automatic Multi-step Reasoning and Tool-use (ART) techniques.
The Tools Connectors and Skills technique is ideal for tasks that require external tools or databases to enhance the model’s capabilities. By integrating specialized knowledge or functionalities, we can guide the model to generate more accurate and nuanced responses. This technique is particularly useful for domain-specific tasks that benefit from leveraging external resources to improve the model’s outputs.
To implement the Tools Connectors and Skills technique using Haystack 2.0, we can create a custom pipeline that integrates external tools or databases to enhance the model’s capabilities. We can then use this pipeline to guide the model to generate more accurate and nuanced responses by leveraging specialized knowledge or functionalities.
Below is an example of how to implement the Tools Connectors and Skills technique using Haystack 2.0 pipelines and the OpenAI GPT-3.5-turbo model. In this example, we perform a web search to retrieve relevant information from external sources and use this information to guide the model’s outputs. The code below assumes you have a Serper API key to perform web searches.
The key steps we will follow are:
Below is a complete example of how to implement the Tools Connectors and Skills technique using Haystack 2.0:
from haystack import Pipeline
from haystack.components.builders.prompt_builder import PromptBuilder
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.generators import OpenAIGenerator
from haystack.components.websearch import SerperDevWebSearch
load_dotenv(".promptenv")
openai_key = os.getenv("OPENAI_KEY")
serper_key = os.getenv("SERPER_KEY")
# Initialize components
web_search = SerperDevWebSearch(api_key=serper_key, top_k=2)
link_content = LinkContentFetcher()
html_converter = HTMLToDocument()
# Initialize a prompt template
template = """Given the information below: \n
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer question: {{ query }}. \n Answer:"""
prompt_builder = PromptBuilder(template=template)
llm = OpenAIGenerator(api_key=openai_key,
model="gpt-3.5-turbo")
# Initialize a pipeline
pipe = Pipeline()
pipe.add_component("search", web_search)
pipe.add_component("fetcher", link_content)
pipe.add_component("converter", html_converter)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", llm)
# Connect the components
pipe.connect("search.links", "fetcher.urls")
pipe.connect("fetcher.streams", "converter.sources")
pipe.connect("converter.documents", "prompt_builder.documents")
pipe.connect("prompt_builder.prompt", "llm.prompt")
# Draw the pipeline
pipe.draw("web_search.png")
This is what the pipeline looks like:
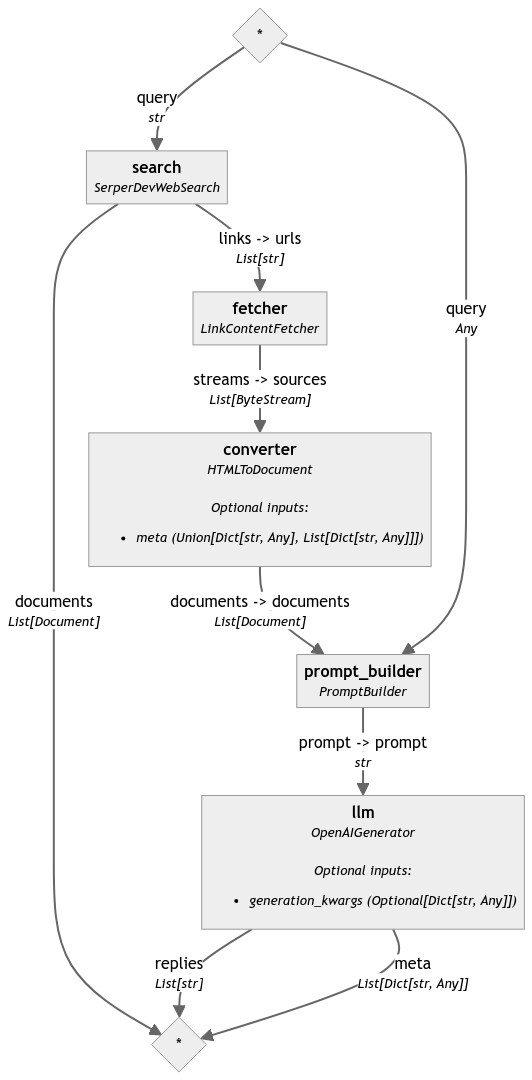
The pipeline above can be executed as follows:
query = "What is the most famous landmark in Berlin?"
result = pipe.run(data={"search":{"query":query}, "prompt_builder":{"query": query}})
The pipeline will generate a response that incorporates information retrieved from external sources, guiding the model to generate more accurate and nuanced outputs. Below is an example:
print(result['search']['documents'][0].content)
>> 'Brandenburg Gate'
print(result['search']['documents'][0].meta)
>> {'title': "Top Berlin's landmarks - IHG",
'link': 'https://www.ihg.com/content/gb/en/guides/berlin/landmarks'}
print(result['llm']['replies'])
>> ['The most famous landmark in Berlin is the Brandenburg Gate.']
The workflow above enables us to incorporate the internet as an external tool that can perform searches programatically and guide the model’s outputs effectively. This is particularly useful for tasks that require up-to-date or detailed domain-specific information, where leveraging external knowledge can lead to more accurate and nuanced responses.
We will now explore the Automatic Multi-step Reasoning and Tool-use (ART) technique and how it can be implemented using Haystack 2.0.
The Automatic Multi-step Reasoning and Tool-use (ART) technique is designed for tasks that benefit from automatic reasoning and the use of external tools or databases in a multi-step process. This technique is particularly useful for complex problem-solving tasks that require the model to perform multiple reasoning steps and leverage external resources to arrive at a solution. In essence, this technique combines Chain of Thought and Tools Connectors and Skills to guide the model through a multi-step reasoning process while leveraging external knowledge or functionalities.
As an example, we may ask an LLM to choose the most recent result from a web search when answering the question. Below is a modified version of our prompt template:
template = """Let's think step by step, and use external resources to guide our reasoning.
Your answer should be weighed by the relevance to today's date\n
{% for document in documents %}
{{ document.content }}
{% endfor %}
Answer question: {{ query }}. \n
Answer:"""
We can then pass this template:
prompt_builder = PromptBuilder(template=template)
llm = OpenAIGenerator(api_key=openai_key,
model="gpt-3.5-turbo")
# Initialize a pipeline
pipe = Pipeline()
pipe.add_component("search", web_search)
pipe.add_component("fetcher", link_content)
pipe.add_component("converter", html_converter)
pipe.add_component("prompt_builder", prompt_builder)
pipe.add_component("llm", llm)
# Connect the components
pipe.connect("search.links", "fetcher.urls")
pipe.connect("fetcher.streams", "converter.sources")
pipe.connect("converter.documents", "prompt_builder.documents")
pipe.connect("prompt_builder.prompt", "llm.prompt")
Whereas the pipeline remained the same, the prompt has been adjusted to ensure that the LLM not only uses a tool, but also incorporates the most recent information from the web search.
Let’s execute the pipeline and assess the sources and the response:
query = "what are the potential short-term and \
long-term impacts of the recent regulatory \
announcements on Bitcoin and Ethereum prices? \
Consider both the market's reaction to \
regulatory news and the technological \
advancements in blockchain that might \
affect these cryptocurrencies"
result = pipe.run(data={"search":{"query":query},
"prompt_builder":{"query": query}})
print(result['llm']['replies'])
"""
1. Short-term impacts:
a. Market reaction to regulatory news: In the short term,
regulatory announcements can lead to increased volatility
and uncertainty in the cryptocurrency market.
Negative or restrictive regulations, such as bans or stricter
regulations on cryptocurrency trading, can negatively impact
the prices of Bitcoin and Ethereum. Investors may react by
selling off their holdings, leading to a temporary decline in prices.
On the other hand, positive or supportive regulations,
such as clarity on legal status or regulatory frameworks,
can have a positive impact on prices, as it increases investor confidence and adoption.
Technological advancements in blockchain:
Technological advancements in blockchain can also impact the
short-term prices of Bitcoin and Ethereum. For example,
the introduction of new scaling solutions like the Lightning
Network for Bitcoin or Ethereum 2.0 upgrade can improve the
scalability and transaction speed of these cryptocurrencies.
Positive developments in these technological advancements can lead to
increased adoption and investor interest, positively impacting prices in the short term.
Long-term impacts:
a. Market reaction to regulatory news: Long-term impacts of
regulatory announcements on Bitcoin and Ethereum prices
depend on the nature of the regulations and the market's
perception of their impact on the cryptocurrencies.
If the regulatory framework is seen as favorable and
supportive of the growth and adoption of Bitcoin and
Ethereum, it can contribute positively to their long-term prices.
On the other hand, if regulations become excessively burdensome
or restrictive, it may hinder innovation and adoption, potentially
impacting prices negatively over the long term
b. Technological advancements in blockchain:
The long-term impacts of technological advancements in blockchain
on Bitcoin and Ethereum prices can be significant.
Advancements like improved scalability,
privacy features, interoperability, and smart contract capabilities
can enhance the value proposition of these cryptocurrencies,
attracting more users and investors over time. If Bitcoin and
Ethereum continue to evolve and adapt to technological advancements,
it can contribute positively to their long-term prices.
To gather more accurate and up-to-date information on this topic,
it is recommended to consult external resources such
as financial news websites, cryptocurrency market analysis platforms,
industry reports, and regulatory announcements from relevant authorities."
"""
Here are the sources the LLM used:
print(result['search']['documents'][0].meta)
>> {'title': 'Long and short-term impacts of regulation in the cryptocurrency market',
'link': 'https://www.sciencedirect.com/science/article/abs/pii/S1062976921000934',
'attributes': {'Missing': 'advancements | Show results with:advancements'},
'position': 1}
print(result['search']['documents'][1].meta)
>> {'title': '[PDF] Long and short-term impacts of regulation in ... - Archive ouverte HAL',
'link': 'https://hal.science/hal-03275473/document',
'date': 'Aug 2, 2023',
'position': 2}
This example showcased how to combine Chain of Thought Prompting and Tools Connectors and Skills to guide the model through a multi-step reasoning process while leveraging external knowledge or functionalities. By incorporating the most recent information from a web search, we can guide the model to generate more accurate and nuanced responses, particularly for complex problem-solving tasks that require multiple reasoning steps and the use of external resources.
We will now apply the Self-Consistency technique and guide the model to generate multiple answers and select the most consistent one. For the next example, we will only share the prompt template.
The Self-Consistency technique is applied to improve the reliability of answers by having the model generate multiple answers and select the most consistent one. This technique is particularly useful for tasks that require the model to generate reliable and consistent responses, such as fact-checking or information verification. By prompting the model to generate multiple answers and evaluate their consistency, we can ensure that the model’s outputs are reliable and aligned with the user’s requirements.
Below is a prompt template that can be used for this purpose:
self_consistency_template = """
Let's explore this question from multiple angles to ensure accuracy.
First, approach the question as if explaining to a beginner.
Next, tackle it with expert-level detail.
Finally, address it from a common-sense perspective.
Compare these responses to assess consistency and reliability.
If all three approaches yield similar conclusions, we can be more confident in the accuracy of the information.
This method helps us triangulate the truth, ensuring that our final answer is not only well-considered
but also verifiable across different levels of complexity and understanding.
Question: {{ query }}?
"""
The Reflection technique is useful for tasks that require the model to evaluate or improve its own responses by considering its answers critically. This technique is particularly effective for tasks that involve self-assessment or self-improvement, such as feedback generation or performance evaluation. By prompting the model to reflect on its own responses and consider them critically, we can guide the model to generate more accurate and nuanced outputs.
Here’s an example prompt template for the Reflection technique:
reflection_template = """
Review your initial answer to the question, considering its correctness, coherence, and factual accuracy.
Reflect on whether the reasoning provided is logically consistent and relevant.
If any part of the response seems incorrect or could be improved, revise the answer
to enhance its clarity, accuracy, and relevance.
This reflective process should lead to a more refined and reliable final response.
Use this opportunity to self-edit and correct any potential errors
identified during your reflection.
Question: {{ query }}?
"""
The Expert Prompting technique is best suited for domain-specific tasks where leveraging specialized knowledge can lead to more accurate and nuanced responses. This technique involves providing the model with expert-level prompts or domain-specific information to guide its outputs. By leveraging specialized knowledge or expertise, we can ensure that the model’s responses are aligned with the requirements of the specific domain or task.
Here’s an example prompt template for the Expert Prompting technique:
expert_prompt_template = """
You are an expert in [specific field or discipline].
Given your expertise, how would you address the following question?
Please synthesize knowledge from various subfields or related disciplines
to provide a comprehensive, informed answer.
Consider the implications, methodologies, and perspectives that a seasoned
professional in this area would take into account. Your response should reflect
a deep understanding of the subject matter, incorporating a range of
expert viewpoints for a well-rounded perspective.
Question: {{ query }}?
"""
The Chains and Rails technique is effective for guiding the model through a series of logical steps or ensuring it stays on track within a specific problem-solving framework. This technique is particularly useful for tasks that require the model to follow a structured approach or adhere to a specific logical sequence. By providing a series of prompts that guide the model through a logical chain of thought, we can ensure that the model’s outputs are consistent and aligned with the user’s requirements.
Here’s an example prompt template for the Chains and Rails technique:
chains_and_rails_template = """
Step 1: Analyze the initial component of the problem,
focusing on {{element1}}. Summarize your findings.
Step 2: Based on Step 1's summary, evaluate {{element2}},
identifying key factors that influence the outcome. Document these insights.
Step 3: With insights from Step 2, develop a strategy for {{element3}},
considering any potential challenges or advantages highlighted previously.
Continue this process, ensuring each step is informed by the outcome of
the previous one.
After the final step, synthesize the information gathered at each stage
to formulate a comprehensive solution, addressing the complex task holistically.
This methodical approach ensures a deep understanding and thorough resolution,
utilizing the interconnectedness of each task to build towards the final outcome.
Question: {{ query }}?
"""
Within Haystack 2.0 we can pass element1, element2, and element3 as parameters to the prompt template when executing the pipeline.
The Automatic Prompt Engineering (APE) technique is ideal for optimizing the prompt creation process in terms of efficiency and effectiveness, especially in scalable or dynamic application contexts. This technique involves automating the prompt creation process to generate prompts that are tailored to the specific requirements of the task or domain. By leveraging automated prompt engineering, we can ensure that the model’s outputs are aligned with the user’s needs and that the prompt creation process is efficient and effective.
Below is a sample prompt:
ape_template = """
Create a set of diverse prompts for {{task}},
each designed to elicit a unique aspect of the required response.
Next, evaluate these prompts based on clarity,
specificity, and their potential to generate the desired outcome.
Identify the most effective prompt and refine it for optimal performance.
This process of generation, evaluation, and
refinement should iterate until the highest quality prompt
is developed, leveraging the model's self-assessment
capabilities to automate the enhancement of prompt design.
Question: {{ query }}?
"""
To measure the effectiveness of the prompts, we can leverage Haystack 2.0 through the use of Document metadata and scores. We can then use these scores to evaluate the effectiveness of the prompts and refine them for optimal performance. For more information, review the Haystack 2.0 documentation.
The Retrieval Augmented Generation (RAG) technique enhances model responses with external knowledge, making it ideal for scenarios where up-to-date or detailed domain-specific information is critical. This technique involves integrating external knowledge sources to guide the model’s outputs, ensuring that the generated text is accurate, relevant, and aligned with the user’s requirements. By leveraging external knowledge, we can enhance the model’s responses and provide more comprehensive and informed outputs.
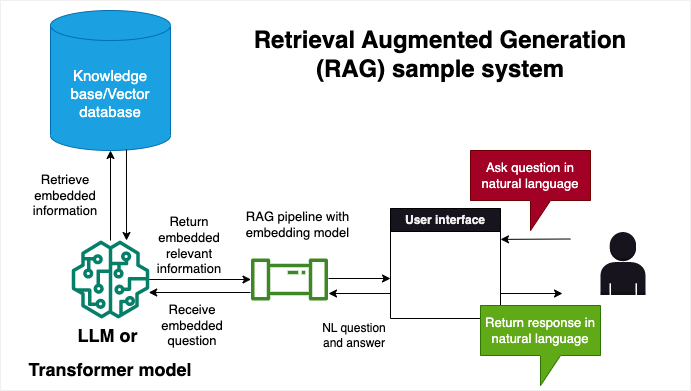
This technique is more advanced, as it requires understanding how to integrate external knowledge sources into the model’s responses and techniques such as tokenization, vectorization, and retrieval-based methods.
Below are two diagrams for a RAG system that consists of an indexing pipeline (process in charge of transforming text into vectors and storing them in a database) and a query pipeline (process in charge of transforming the question into a vector and retrieving the most relevant documents from the database).
The pipeline below transforms audio into text through OpenAI’s Whisper component, cleans the text, tokenizes it and stores it into a document store.

The pipeline below retrieves the most relevant documents from the document store, tokenizes the question, and retrieves the most relevant documents from the document store.
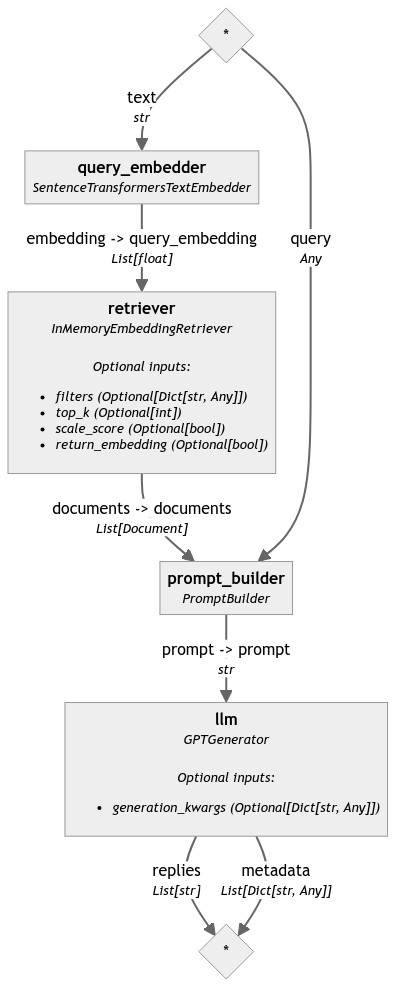
For a detailed example of how to implement the RAG technique using Haystack 2.0, refer to this Haystack 2.0 tutorial on how to build a question and answer system with RAG.
In this blog, we explored the paper “Prompt Design and Engineering” by Xavier Amatriain, which provides a comprehensive examination of prompt engineering for large language models (LLMs). We discussed the key techniques in prompt engineering, including Chain of Thought, Tree of Thought, Tools Connectors and Skills, Automatic Multi-step Reasoning and Tool-use, Self-Consistency, Reflection, Expert Prompting, Chains and Rails, Automatic Prompt Engineering, and Retrieval Augmented Generation. We demonstrated how to implement these techniques using Haystack 2.0 and LLM providers, providing code examples and practical applications for each technique. By leveraging these techniques, developers can guide LLMs to generate more accurate, relevant, and nuanced responses, ensuring that the model’s outputs are aligned with the user’s requirements. We hope this blog provides a valuable resource for developers looking to apply prompt engineering techniques in their AI development projects.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

