


Rails allows anyone to build a blog engine in 15 minutes; how would this translate to the Machine Learning development world? This post represents my vision of what a Ruby on Rails for Machine Learning should look like.
I’ve been talking to many data practitioners these past few months, from Ploomber users to maintainers of other data tools. A recurrent topic has been the state of the Machine Learning tooling; discussions often revolve around the proper API for a Machine Learning framework.
I wonder if the same type of discussions happened during the early days of the internet when web development frameworks appeared. My first encounter with web development was when I learned about the LAMP stack. Out of curiosity, I learned the basics of PHP, JavaScript, HTML, and CSS, but I found it too difficult to stitch them together to build a website. There were just too many ways of doing the same thing, and most of them seemed incorrect. At that point, I thought: one must learn a lot even to build a simple website. Then, I learned about web frameworks while taking an online course on software engineering: it was such a delightful experience!
The course showed how to develop a software application using Ruby on Rails. I didn’t know much about web technologies, but the framework made it much easier for me: it reduced the number of decisions I had to make and provided a consistent path to get things done. I tried a few other frameworks, such as Django, but none matched Rails' development experience; it’s no surprise that the first pillar of The Rails Doctrine is Optimize for programmer happiness.
Fast forward, I started working on Machine Learning projects and felt like I was on the inefficient route again. There were many ways of achieving the same thing, with most of them feeling incorrect.
We refer to projects such as scikit-learn, PyTorch, or Tensorflow as Machine Learning frameworks. Still, they are Machine Learning training frameworks because doing Machine Learning is much more than training a model; this is equivalent to calling ORM frameworks, web frameworks.
Web frameworks allowed individuals to develop web applications quickly, but we currently need a whole team to build and deploy Machine Learning models. I’m sure that at this point, you’ve heard the 87% Machine Learning projects fail statistic more than a dozen times.
Simplifying the development of Machine Learning models is the promise of new tools, but many are going in the wrong direction. For example, some tools claim to take down the 87% statistic by versioning data, scaling experiments, or automating model deployment. Still, in my experience, most projects fail for other reasons. We’re pouring too many resources into solving peripheral problems instead of tackling the root cause.
Putting business problems aside (which are the number one reason why an ML project never makes it to production), there are certainly a few technical problems where better tooling can make a huge difference. In my experience, what sabotages projects is the lack of development processes: lack of code organization and packaging standards, undocumented dependencies, broken computational environments, a mismatch between training and serving data pre-processing, and poorly integrated pipelines; such problems cause projects to build upon fragile foundations, making it challenging to convert a model prototype (commonly developed in a notebook) into a production-ready artifact.
The following sections describe how I think the experience of a Ruby on Rails for Machine Learning should look like.
No one starts a web application from zero, yet, whenever we begin a Machine Learning project, we usually start with a few files (or notebooks) and build from there. Furthermore, starting from scratch causes each project to have a particular layout, which difficulties onboarding as people have to learn each project’s structure. In contrast, when using a web framework, we instantly know where to find things if we had used that framework in the past.
Projects such as cookiecutter-data-science are a great way to bootstrap projects. However, I believe project layouts can do a lot more if they integrate with a framework. For example, Rails users can significantly reduce configuration parameters by following certain conventions on project structure and file naming.

Standardization of project layout is a significant first step. A natural second step is to take a project in a standard form and easily convert it into a deployment artifact. Once you develop a web application with a specific framework, you can quickly deploy it using a sheer of PaaS services. In contrast, the data science world is filled with Docker for Data Science tutorials, which are unfortunately necessary to show how to package ML work to run it in production. A data scientist should not have to learn Docker. Instead, a framework should create a Docker image (or Python package) for deployment without the data scientist ever having to deal with those details.
Another example of poor automation is when data scientists write Flask applications for online serving. Once the serving logic is defined, a framework should generate all the supporting code to integrate the serving pipeline in a more extensive system; this can be a REST API but may take other forms.
Deployment automation is the objective of many new tools. Still, I consider they provide an incomplete and error-prone workflow. For example, Mlflow’s documentation shows that to deploy a scikit-learn model; we must provide the following files:
my_model/
├── MLmodel
├── model.pkl
├── conda.yaml
└── requirements.txt
A model file (model.pkl) is not a complete inference artifact. In the majority of cases, serving pipelines involve custom pre-processing (i.e., generating features). And while MLflow supports arbitrary functions as models, such functionality hides in a small section. Thus, rather than thinking of model files as deployment artifacts, a framework should consider the project as a whole: configuration, model file, and dependencies.
To deploy a model, I have a small bash script that creates a .zip artifact with all necessary files; a second script deploys the model using such compressed file:
unzip my-ml-pipeline-v-1-2.zip
pip install -r my-ml-pipeline-v-1-2/requirements.lock.txt
And then, import my model into the application:
from my_ml_pipeline import Model
model = Model()
model.predict(input_data=input_data)
Here my deployment artifact contains everything required to set up the project, and the exposed API abstracts all the details (which model to load, pre-process data and finally call the model).
A strict separation between configuration and code is considered a best practice in software development. Yet, this doesn’t happen in many ML projects where it’s common to find cloud configuration settings (e.g., connecting to an S3 bucket) interleaved with the data processing code (e.g., NumPy or pandas operations). Configuration and code separation allows us to run our code under different settings, simplifying testing and execution.
For example, to enable continuous integration, we may want to run our pipeline with a sample of the raw data and store results in a specific S3 bucket for testing purposes. However, we want to use the entire dataset and store artifacts in a different bucket when training models. Rails defines a development, test, and production environment by default; we can apply the same idea to ML projects to help users run their workflows under different configurations depending on their objective: test pipeline, train model, or serve model.
A strict separation between configuration and code opens the door to another essential feature: seamless transition from a local environment to the cloud. While not necessary in all projects, sometimes we may want to scale up our analysis (e.g., run in multiple processes or a cluster) to speed up computations. Thus, frameworks should allow users to move from a local environment to a distributed one by changing the project’s configuration without code changes.
Running things in the cloud has the disadvantage that we lose the ability to debug errors interactively. For example, in past experiences when debugging a pipeline, logs didn’t provide enough information, so I had to download artifacts from remote storage, replicate the error locally, and use the Python debugger. Therefore, frameworks must ensure that dependency installation is deterministic (i.e., identical versions), provide a way to download remote artifacts, and resume execution locally from the point of failure.
Training-serving skew is one of the most common problems when deploying Machine Learning models. The problem appears when processing raw data at serving time is not the same as training time. An effective way to prevent it is to share as much code as possible during training and serving time.
The only difference between training and a serving pipeline is that the former gets historical data, processes it, and trains a model. In contrast, the latter gets new data, processes it, and makes predictions.
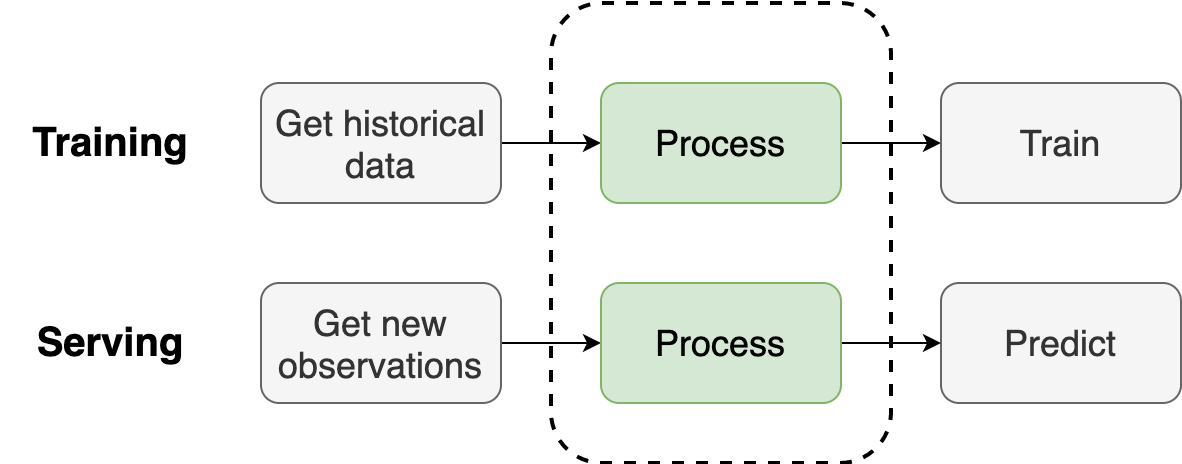
As you can see, everything that happens in the middle is (and must be) the same to prevent training-serving skew. A Rails for ML should allow users to turn their training pipeline into serving ones for batch or online processing.
Tabular data is the most common use case of applied Machine Learning. However, tabular data usually needs a lot of pre-processing before training a model. Lots of pre-processing implies that most of the project’s code is data preparation, yet, many frameworks focus on model training, but creating a training set is the most challenging and time-consuming part of training a model on tabular data!
Libraries such as pandas allow users to query and dump data from data warehouses but do not automate the entire workflow, causing data scientists to write custom Python code to manage connections downloading data, or parametrize SQL queries. A framework that simplifies the integration between SQL and Python helps produce cleaner pipelines by removing all that extra (often inefficient) code that most projects have.
Ruby has a fantastic tool called Bundler that records dependency versions when setting up the environment. Developers list their dependencies in a Gemfile (similar to a pip’s requirements.txt) and then run bundle install. In Python, this requires two steps, first install the dependencies pip install -r requirements.txt and then recording the installed versions with pip freeze > requirements.lock.txt. However, this isn’t standard practice, is a two-step process, and isn’t robust. Bundler provides stronger guarantees to prevent us from breaking our dependency installation since it stores extra information that a requirements.txt file does not contain. The Pipfile project aims to solve these limitations in the Python ecosystem, but it isn’t ready yet; in the conda world, there is another similar project. Dependency management is a broader problem applicable to any Python project, so I think a general solution (not tied up to any specific framework) is the best way to move forward.
A second important consideration is the management of development and production dependencies. For example, we may use development libraries (e.g., an experiment tracker) that we don’t need when serving predictions. Therefore, an ML framework should ensure minimal dependencies in production for faster builds and diminish the chance of unsolvable environments.
Most tools market themselves in terms of scalability instead of user experience. Performance and scalability are essential, but we’re throwing it too early in the process. Most ML projects don’t even reach a point where scalability is an issue because they never hit production.
Just like the Rails doctrine, we should put data scientist’s happiness first. In the data world, this translates into a tool that allows us to run more experiments quickly. But bear in mind that by experiments, I do not mean train more models, but a broader definition of an experiment: process more training data, improve data cleaning code, add new features, etc.
Another aspect of user’s happiness is to let them use whatever tool they feel the most comfortable with. Do they like Jupyter? Let them use it, but fix the problems that prevent code written in notebooks from being production-friendly. I love notebooks. Anything else feels like a step backward; forcing me to write my data processing code in a class makes me unhappy because I lose the ability to make incremental progress.
Rails has a console that allows users to quickly test out ideas without touching the website. Upon initializing the console, users have access to an app object that they can use to interact with their application for experimentation or debugging. Other projects have similar consoles (Django, Flask).
A console has been one of the most time-saving features that I developed for Ploomber. A pipeline can be represented as a directed acyclic graph, and interacting with it to extract information makes development a lot more transparent.
A few weeks ago, I was onboarding a colleague to a project I’m working on. The pipeline has about 50 tasks from data dumping, cleaning, feature engineering, and model training. Instead of showing her the source code files, I started an interactive session, and we navigated through the pipeline. After a few minutes, she had a high-level idea of the pipeline; but more importantly, she could start an interactive console and explore the pipeline to understand its structure and dive deep into the source code if needed.
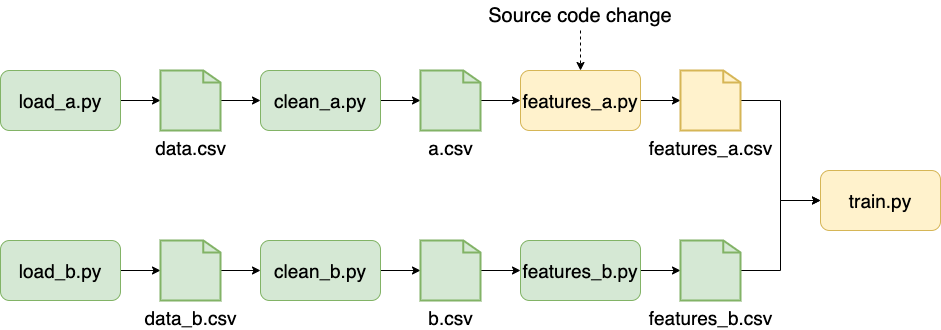
Machine Learning pipelines progress in tiny steps. Therefore, it is a waste of time to repeat all computations with every minor change. That’s why some people use tools like Make to track source code changes and skip executing scripts whose source code hasn’t changed. Cutting execution of unchanged tasks is an essential feature for rapid iteration, yet, most pipeline frameworks do not implement it or have a basic hash-based implementation.
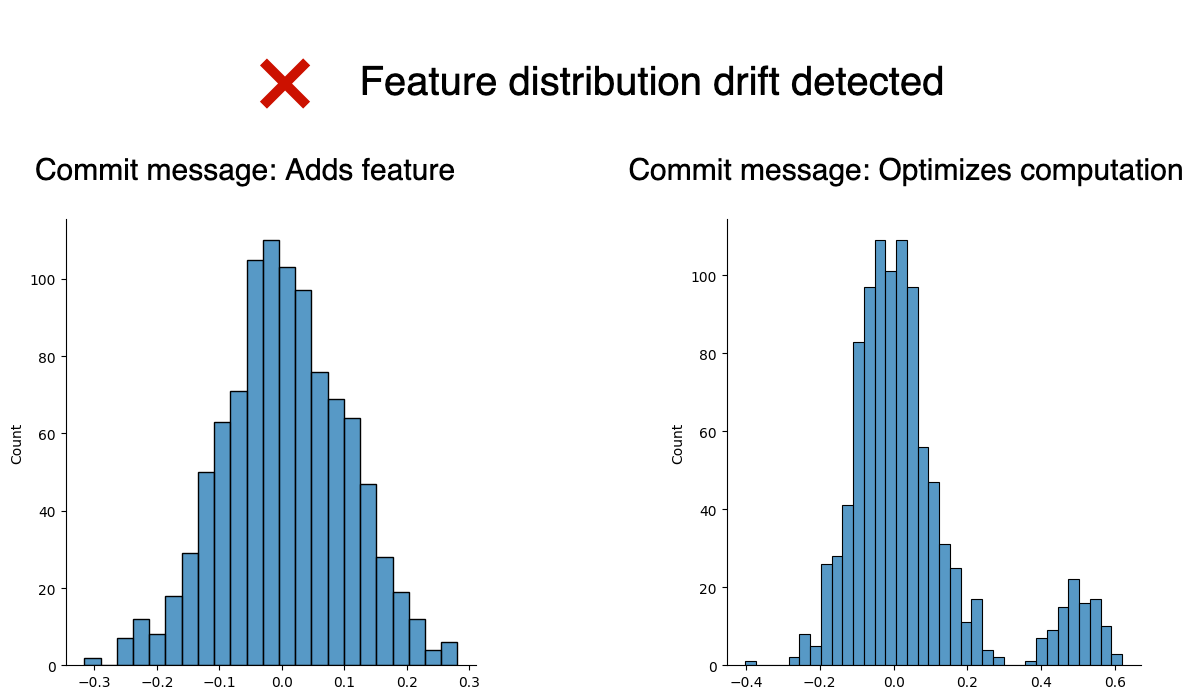
Models degrade over time, and it’s critical to re-train them frequently. Recently, there’s been a surge in ML model monitoring tools to tackle that problem and alert us to re-train a model. What’s been mostly overlooked is continuously assessing the quality of a model before we deploy it. Traditional unit testing doesn’t work because even with the same input data, a training procedure will generate a model with different learned parameters, thus, causing a slightly different prediction for the same input data.
On the other hand, setting the seed is useless because reference values will be outdated as soon as we change anything in the training procedure (e.g., add more data). Furthermore, we don’t want to test that our training code produces the same model every time, but that outputs a high-quality model. Thus, my approach is to use predictions from the current model in production as reference values, then test how different those predictions are from a candidate model. This approach has allowed me to quickly discard low-quality models and spot errors, such as training on corrupted data; however, this process remains partially manual.
ML frameworks can automate model evaluation by assessing model quality by comparing it with a reference model. However, automated testing can go beyond model evaluation. For example, to alert users when a code change introduces a drastic change in the distribution of a model feature. Automated testing could even check for memory consumption or runtime increases and alert us on any degradation.
Automated testing has a great potential to improve the quality of data pipelines without requiring data scientists to write testing code.
We’re working hard to make Ploomber a delightful experience to build Machine Learning projects, please show your support with a star on GitHub.
If you want to be part of the journey, please join our community or subscribe to our newsletter.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

