



We found this cool research paper about notebook reproducibility and had to make it run in production.
Most (90%) of the Jupyter notebooks out there aren’t reproducible due to missing requirements.txt or missing dependency versions. We’ve used the SnifferDog tool to make sure ours is and included requirements.txt in all of our git repos.
This blog post will describe the solution and architecture, a simple way that you can use to make sure the jupyter notebooks you are using are reproducible and the motive behind it. The solution involves using our open-source fork to SnifferDog repo (which is based on an academia research paper). I’ve fixed some issues in the code, made sure it runs with the latest python and recreated the API Bank that was corrupted. I had to go over the most popular python packages and crawl them for different releases. Let’s get started!
We’ll need to have python locally installed to run some of the scripts in this blog.
Python can import modules as dependencies like any other programing language. These modules can be internal or external (via pip install ploomber for instance).
When importing and consuming multiple external modules it can get pretty hard to run the notebook (e.g. sharing it with colleagues). To get and run all the appropriate versions that the original author used is very time-consuming and error-prune.
Having all of your dependencies in a local requirements.txt file can make the installation of these modules a piece of cake. It can also help you save tons of time avoiding the packages docs and archive, finding the right version you specifically need.
Requirements have different forms and shapes, below is a sample file, and it’s type in the comment above it.
# requirements.txt
scikit-learn # Latest version (no lock)
pandas==1.3.0 # Specific version
ipywidgets>=4.0.1,<=4.0.2 # Minimum and maximum version
xgboost>=0.72.1,<=0.82
seaborn>=0.12.0rc0,<=0.12.1
numpy
matplotlib
# environment.yml (Conda)
name: my_env
dependencies:
- wget==3.2
- requests>=2.24.0
- networkx
Resources: requirements.txt, environment.yaml, Pipfile.lock
This is how the architecture looks like:
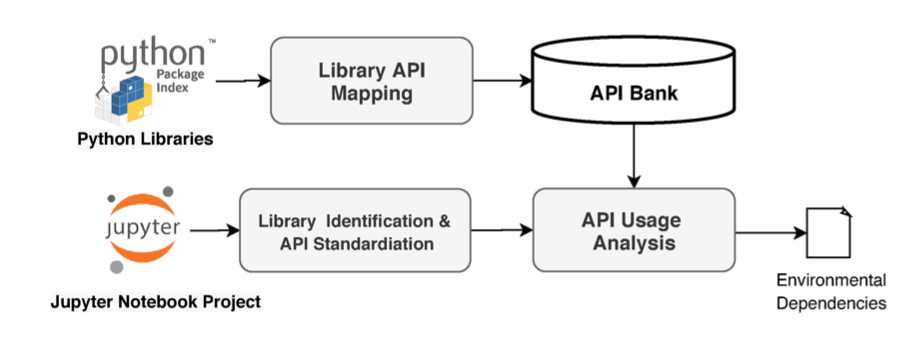 (Taken from: Restoring Execution Environments paper)
(Taken from: Restoring Execution Environments paper)
The API Bank is a collection of json mappings that was crawled on multiple python packages and versions. Each of those are statically analysed per release and includes the specific function signatures which is then being saved into json files (this is zipped in the original repo to lower the size of the repo). The sample notebook is then going through a static analysis, being parsed and its imports are being extracted as part of the script. Once this stage is done, the dependencies are cross-referenced with the API Bank json files and on matches the specific version is printed out. The result is an output prompt with the environment dependencies, which can be saved into a requirements.txt file and make your environment reproducible and your notebook runable. Without it, we’d have to try different versions in our environment until we can run the notebook without exceptions or code breaks.
Let’s start by cloning the Sniffer repo sample:
# Get the fixed sniffer version
git clone https://github.com/ploomber/SnifferDog.git ploomber_sniffer
The whole library is based on a dependency bank which can rapidly get to hundreds of MBs. To run we’ll need to unzip it first:
unzip API_bank.zip -d API_bank
Now we’re good to go!
In here we will run on a sample notebook that can be found in the repository: sample_notebooks/xgboost.ipynb.
In the end, once the process is done (takes less than 1 minute), we’ll get an output of the dependencies file, this should look like the prompt below:
# requirements.txt
scikit-learn
xgboost>=0.72.1,<=0.82
seaborn>=0.12.0rc0,<=0.12.1
pandas>=1.3.0,<=1.5.1
ipywidgets>=4.0.1,<=4.0.2
numpy
matplotlib
To generate the above requirements, we can run the following command:
python ploomber_sniffer/lib_ver_producer.py sample_notebooks/xgboost.ipynb
We can now take this output requirements.txt and save it as part of our project. Our sample notebook is based on specific pandas and seaborn versions as it was taken from this Xgboost workshop. This code was written 7 years ago and a lot can change during this time. We’ll see later how running this notebook out of the box with the latest packages can break and stop your work until you get the environment correctly (i.e. pandas/xgboost breaks due to version mismatch).
Now, if we create an environment with the same requirements.txt packages but without the version lock, i.e:
# requirements.txt
scikit-learn
xgboost
seaborn
pandas
ipywidgets
numpy
matplotlib
In this case I’ll use conda to create a python 3.10 environment and install this requirements.txt file:
conda create -n py310 python=3.10
conda activate py310
pip install -r requirements.txt
We’ll see the notebook breaks and doesn’t run the cells (cell 5), we’re getting sklearn needs to be installed in order to use this module:
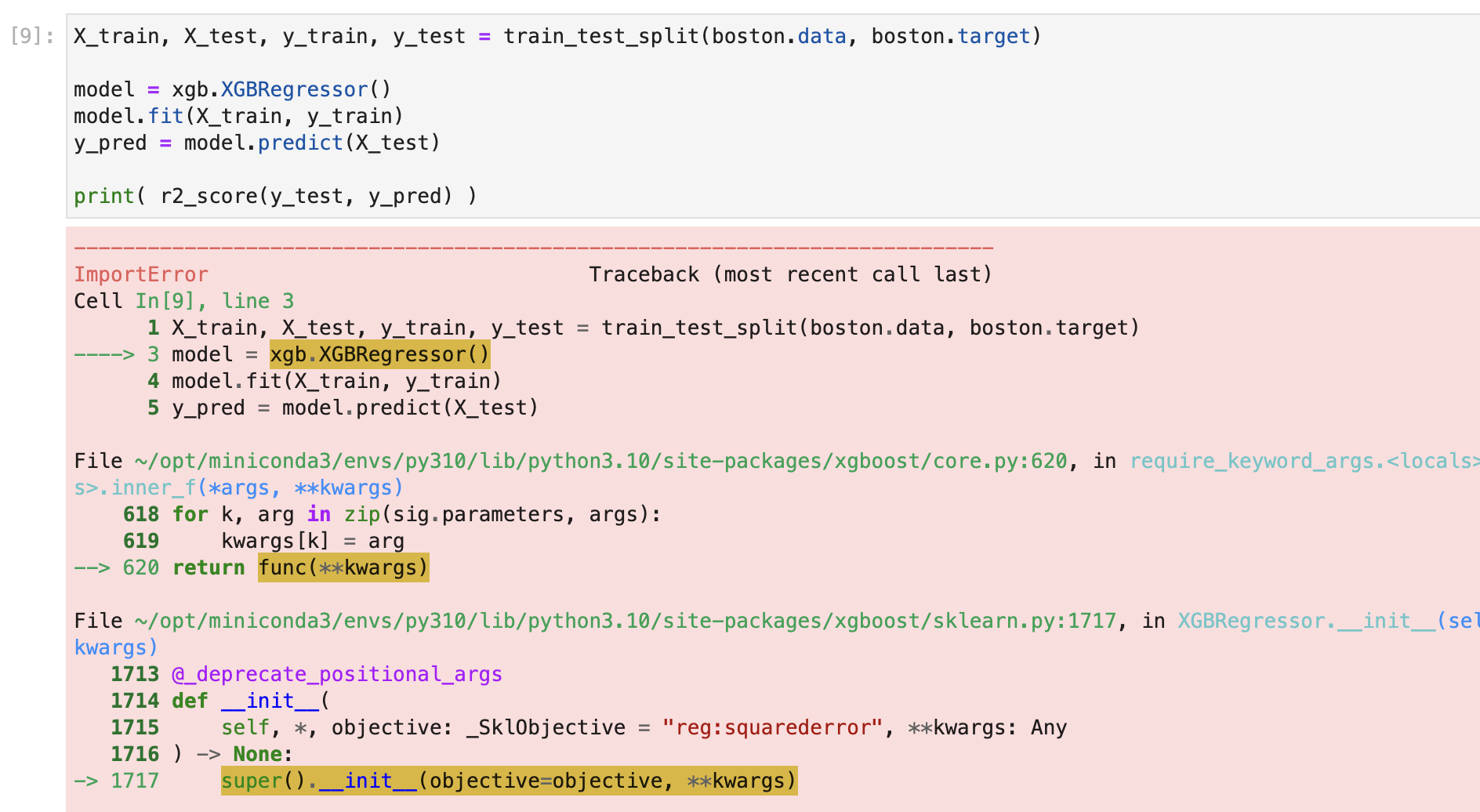
In that case, SnifferDog was able to detect a specific version change that happened between the latest version and version 0.72 - 0.82.
The problem here is that Xgboost in the latest version (1.7.1) is looking for the sklearn module to initialize the class and can’t find it.
In the 0.81 version the class has a different reference name for the module so it can’t be found in the newer versions.
The different parameters that the class accepts is also different.
latest one:
classxgboost.XGBRegressor(*, objective='reg:squarederror', **kwargs)
0.81:
class xgboost.XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
For more information, check out the different docs: 1.7.1, 0.81
Now what we can do is take the output from the earlier step (included below as well), and paste it into the requirements.txt and we’ll see that the notebooks works perfectly now.
# requirements.txt
scikit-learn
xgboost>=0.72.1,<=0.82
seaborn>=0.12.0rc0,<=0.12.1
pandas>=1.3.0,<=1.5.1
ipywidgets>=4.0.1,<=4.0.2
numpy
matplotlib
The notebook should run flawlessly, without any errors.
Congrats, you made your notebook so much easier to install and reproduce!
Sniffer is the easiest way to recreate python environments and start running Data Science and Machine Learning projects. Since it allows you to generate the requirements on the fly, it eliminates the need to track those dependencies manually, or going to the docs and searching for the right dependency/version in case it’s not your notebook.
Do you have any questions? Ping us on Slack!
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

