



In this blog, we’ll review how we took a raw .ipynb notebook that does time series forecasting with Arima, modularized it into a Ploomber pipeline, and ran parallel jobs on Slurm. You can follow the steps in this guide to deploy it yourself. We’ve been using this notebook by @Willie Wheeler.
The notebook is composed of 8 tasks as we’ll see in the graph below. It includes most of the basic steps for modeling - getting the data cleaning it, fitting, hyperparameter tuning, validation, and visualization. As a shortcut, I took the notebook and used the Soorgeon tool to automatically modularize this notebook into a Ploomber pipeline. This extracted all the dependencies into a requirements.txt file, broke the headers into standalone tasks, and created a pipeline out of these modular tasks. The primary benefit of using Ploomber is that it allows me to experiment faster since it caches results from previous runs, plus, it makes it simple to submit parallel jobs to SLURM to fine-tune the model.
Start by running this command to clone the example locally (in case you don’t have ploomber, install Ploomber first): I started by bootstrapping my Colab with a few dependencies (pip install ploomber).
ploomber examples -n templates/timeseries -o ts
cd ts
Now you have the pipeline locally, you can perform a sanity check and run:
ploomber status
This should show you all of the steps of the pipeline and its status (Has not been run), this is a reference output:

You can also build the pipeline locally if you’re only interested in the time series piece. Next, we’ll see how we can start executing on our Slurm cluster and how we can have parallel runs.
For simplicity, we’ll show you how to launch a SLURM cluster with Docker, but if you have access to an existing cluster, you can use that one. We’ve created a tool called Soopervisor, which allows us to deploy pipelines to SLURM and other platforms such as Kubernetes, Airflow, and AWS Batch. We’ll be following the Slurm guide here.
You have to have a running docker agent to launch the cluster, read more here on getting started with Docker.
Create a docker-compose.yml.
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/docker-compose.yml
Once it’s done, spin up the cluster:
docker-compose up -d
We can now connect to the cluster via this command:
docker-compose exec slurmjupyter /bin/bash
Now that we’re inside the cluster, we need to bootstrap it and make sure we have the pipeline we want to run.
Get the bootstrapping script and run it, this is the script to bootstrap the cluster:
wget https://raw.githubusercontent.com/ploomber/projects/master/templates/timeseries/start.sh
chmod 755 start.sh
./start.sh
Get the time series pipeline template:
ploomber examples -n templates/timeseries -o ts
cd ts
Install requirements and add through soopervisor:
ploomber install
soopervisor add cluster –backend slurm
This will create a cluster directory with the template that soopervisor uses to submit Slurm tasks (template.sh).
We execute the export command to convert the pipeline and submit the jobs to the cluster. Once it’s done we can see all of our outputs in the output folder:
soopervisor export cluster
ls -l ./output
We can see here some of the predictions that were generated by the model:
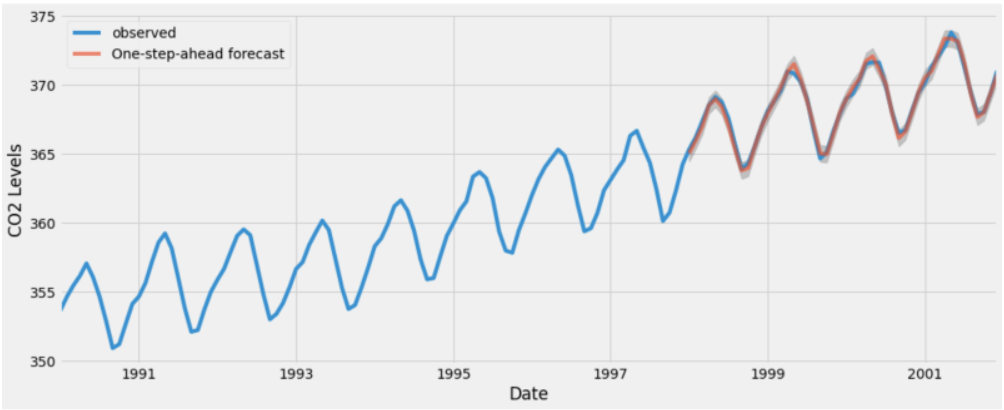
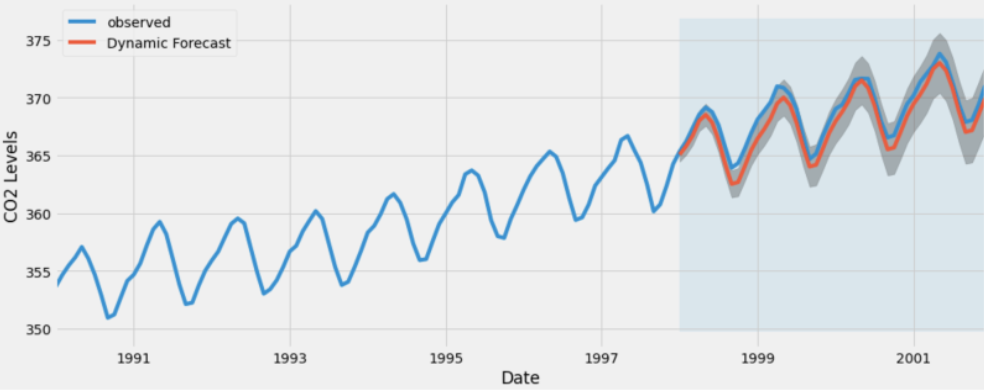
Note that if you’ll run it again, only the tasks that changed will run (there’s a cache to manage it).
Once you’re done, don’t forget to shut down the cluster:
docker-compose stop
This blog showed how to run time series as a modular pipeline that can scale into distribute cluster training. We started from a notebook, moved into a pipeline, and executed it on a SLURM cluster. Once we’re past the stage of an individual working on a notebook (for instance a team, or production tasks) it’s important to make sure you can scale, collaborate and reliably execute your work. Since data science is an iterative process, Ploomber gives you an easy mechanism to standardize your work and move quickly between your dev and production environments.
Make sure to connect with us and hundreds of other community members on slack. If you have any feedback or comments, I’d love to hear them!
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

