


Training-serving skew is one of the most common problems when deploying Machine Learning models. This post explains what it is and how to prevent it.
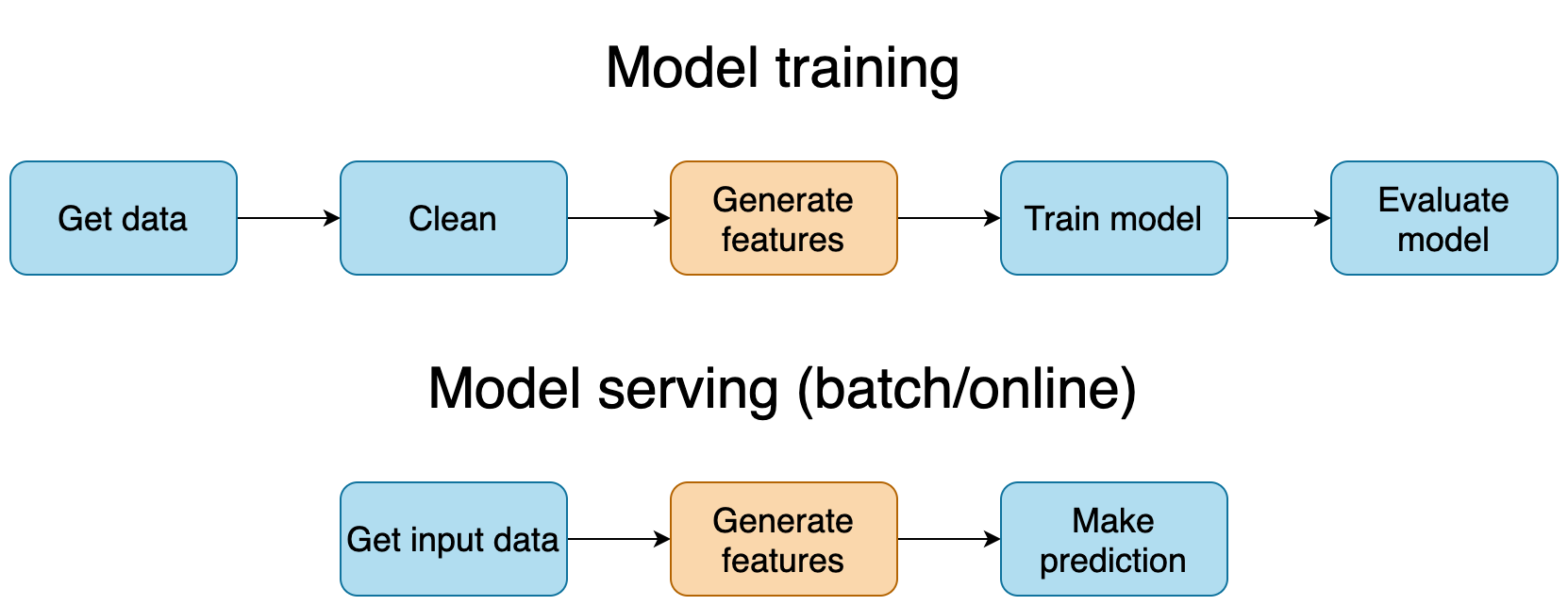
When training a Machine Learning model, we always follow the same series of steps:
Once we clean the data (2), we apply transformations (3) to it to make the learning problem easier. Feature engineering is a particularly important task when working with tabular data and classic ML models (which is the most common setting in industry), the only exception are Deep Learning models, where there is little to no feature engineering. This post focuses on the former scenario.
When deploying a model, the pipelines look very similar, except we make predictions using a previously trained model after computing the features. However, not all deployments are equal, the two most common settings are:
Feature engineering is the set of statistically independent transformations that operate on a single (or group of) observation(s). In practical terms, it means that no information from the training set is part of the transformation.
This contrasts with some pre-processing procedures such as feature scaling, where information from the training set (i.e. mean and standard deviation) is used as part of the transformation (subtract mean, divide by standard deviation). These pre-processing methods are not feature engineering, but part of the model itself: mean and standard deviation are “learned” from the training set and then applied to the validation/test set.
In mathematical terms, we can express the feature engineering process as a function that transforms a raw input into another vector that is used to train the model:
Ideally, we should re-use the same feature engineering code to guarantee that a given raw input maps to the same feature vector at training and serving time. If this does not happen, we have training-serving skew. One common reason for this is a mismatch of computational resources at training and serving time.
Imagine you are working on a new ML project and decide to write your pipeline using Spark. A few months later, you have the first version and are ready to deploy it as a microservice. It would be very inefficient to require your microservice to connect to a Spark cluster to make a new prediction, hence, you decide to re-implement all your feature engineering code using numpy/pandas to avoid any extra infrastructure. All of a sudden, you have two feature engineering codebases to maintain (spark and numpy/pandas). Given an input, you must ensure they the same output to avoid training-serving skew.
This is less of a problem with batch deployments, since you usually have the same resources available at training and serving time, but always keep this situation in mind. And whenever possible, use a training technology stack that can also be used at serving time.
If for any reason, you cannot re-use your feature engineering training code. You must test for training-serving skew before deploying a new model. To do this, pass your raw data through your feature engineering pipelines (training and serving), then compare the output. All raw input vectors should map to the same output feature vector.
Note that training-serving skew is not a universally defined term. For the purpose of this post, we limit the definition to a discrepancy between the training and serving feature engineering code.
If you are able to re-use feature engineering at training and serving time, you must ensure the code is modular so you can integrate it in both pipelines easily, the next sections present three ways of doing so.
The simplest approach is to abstract your feature engineering code in a function and call it at training and serving time:
# train.py
def generate_features(raw_input):
"""Generate features from raw input
"""
# process raw_input...
return features
def train():
X_raw, y = load_data()
X_features = generate_features(X_raw)
clf = RandomForestClassifier()
clf.fit(X_features, y)
save_model(clf)
Then, call your generate_features function in your microservice code, here’s an example if using Flask:
from flask import Flask, request, jsonify
from my_project import generate_features
app = Flask(__name__)
clf = load_model(path_to_model)
@app.route('/predict', methods=['POST'])
def predict():
X_raw = request.get_json()
# cal the same function you used for training
X_features = generate_features(X_raw)
y_pred = clf.predict(X_features)
return jsonify({'estimation': y_pred})
While simple, the first solution above does not offer a great development experience. Developing features is a highly iterative process. The best way to accelerate this is via incremental builds, which keep track of source code changes and skip redundant work.
Say for example you have 20 features that are independent of each other, if you modify one of them, you can skip the rest since they’ll produce identical results if you executed them before.
Workflow managers are frameworks that allow you to describe a graph of computations (such as feature engineering code). There are many options to choose from, unfortunately, only a few of them support incremental builds, Ploomber is one of them. Other options are DVC Pipelines and drake for R.
To enable incremental builds, workflow managers save results to disk, and load them if the source code hasn’t changed. In production, you usually want to perform in-memory operations exclusively because disk access is slow. As far as I know, Ploomber is the only workflow manager that allows you to convert a batch-based pipeline to an in-memory one for deployment without any code changes.
Another solution is to use a feature store, which is an external system that pre-computes features for you. You only need to fetch the ones you want for model training and serving. Here’s an example using Feast, an open-source feature store:
# features to fetch
customer_features = [
'credit_score', 'balance',
'total_purchases', 'last_active'
]
# get historical features
historical = fs.get_historical_features(customer_ids, customer_features)
# train model
model = ml.fit(historical)
# fetch online features (from an in-memory system for low latency)
online = fs.get_online_features(customer_ids, customer_features)
# make predictions
pred = model.predict(online)
A feature store is a great way to tackle training-serving skew. It also reduces development time, since you only need to code a feature once. This is a great solution for batch deployments and some online ones. If your online model expects user-submitted input data (e.g. a model the classifies images from a user’s camera), a feature store is unfeasible.
The main caveat is that you need to invest in maintaining the feature store infrastructure, but if you are developing many models that can benefit from the same set of features, it is worth considering this option.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

