


Update: The second part is available here.
Update: We released soorgeon, a tool that automatically refactors legacy notebooks!
Over the last few months, We’ve talked to many data teams to help them get started with Ploomber to develop maintainable and production-ready pipelines. One question that often comes up is, How do we refactor our existing notebooks? This blog post series provides a step-by-step guide to convert monolithic Jupyter notebooks into maintainable pipelines.
To ensure you know when the second part is out, follow us on Twitter or susbcribe to our newsletter. Let’s get started.
Code that lives in a .ipynb gets real messy fast. Thus, after a few days of the notebook’s creation, it’s common for such files to contain hundreds of cells and dozens of tables and plots.
Such a notebook is what we call a Jupyter monolith: a single notebook that contains everything from data loading, cleaning, plotting, etc. Unfortunately, maintaining a Jupyter monolith is extremely hard because there aren’t clear boundaries among tasks, and there isn’t an easy way to test parts in isolation. So our objective is to turn a messy notebook into something like this:
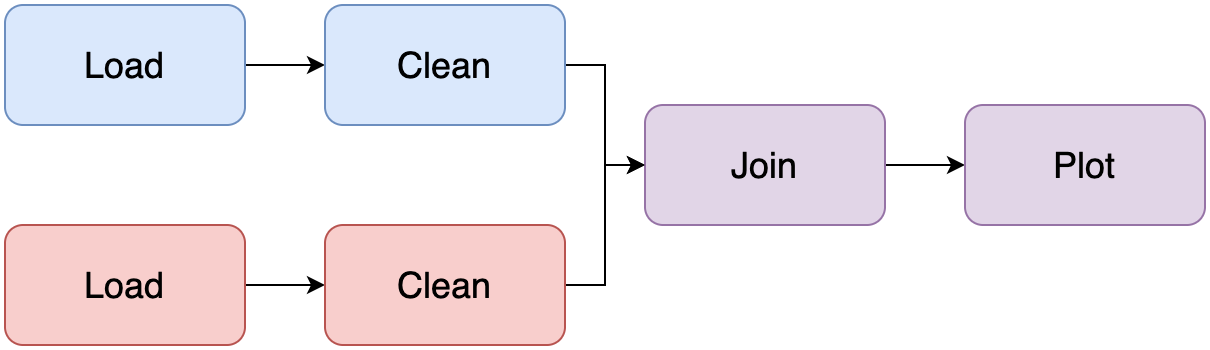
Say your project currently looks like this:
utils.py
plot.py
analysis.ipynb
This file layout is typical: .py files may contain some utility functions, but most of the code lives in the analysis.ipynb notebook. Before refactoring our code, let’s first add three files that will help us test our pipeline:
requirements.txtpipeline.yamlanalysis.ipynb (name it pipeline.ipynb). We create a copy to keep our original output cells as reference.If you already have a requirements.txt, use it. Otherwise, create a file with the following content:
# sample requirements.txt
ploomber
Your pipeline.yaml should look like this:
tasks:
- source: pipeline.ipynb
product: output.ipynb
Then, add the following as the top cell in pipeline.ipynb:
upstream = None
product = None
And tag such cell with parameters. Click here for instructions on cell tagging.
At this point, your project looks like this:
# existing files
utils.py
plot.py
analysis.ipynb
# new files
pipeline.ipynb
pipeline.yaml
requirements.txt
Now, let’s create a virtual environment and run our pipeline. The exact steps for creating a virtual environment depend on the package manager you’re using and the virtual environment manager; here’s some sample code if using pip and venv on Linux/macOS:
# create virtual env
python -m venv my-venv
source my-venv/bin/activate
# install dependencies
pip install -r requirements.txt
# run the pipeline
ploomber build
The pipeline will likely crash due to missing dependencies (i.e., you’ll see a ModuleNotFound error). So first, install any missing dependencies using pip install {name} and add a new line with the package name to requirements.txt; try again until the pipeline runs.
Our requirements.txt file contains the list of dependencies we need to run our project. Still, it doesn’t specify particular versions; consequently, running pip install -r requirements.txt today and running it one month from now will yield a different set of dependency versions (e.g., pandas 1.2 vs. pandas 1.3), potentially breaking our pipeline. To prevent that, execute the following:
pip freeze > requirements.lock.txt
pip freeze prints an exhaustive list of dependencies with their corresponding versions. The next time you run your pipeline, you can do pip install -r requirements.lock.txt to get the same environment that you currently have. Make sure you re-generate requirements.lock.txt whenever you modify requirements.txt.
If you got rid of ModuleNotFound errors, but you still see other types of errors, your pipeline is likely broken due to different reasons. So let’s move to the next stage to fix that.
Data pipelines tend to be long-running processes that may take hours to run. To accelerate the debugging process, we make it fail quickly, fix errors, and repeat.
To enable quick testing, first, add a new variable to your parameters cell in the analysis.ipynb notebook:
upstream = None
product = None
# new line
sample = None
And add a new parameter to your pipeline.yaml:
tasks:
- source: pipeline.ipynb
product: output.ipynb
# new parameter!
params:
sample: True
We want the sample parameter to control whether to use the entire dataset or a sample. Now, locate all the cells in the notebook that are loading or downloading raw data, for example:
import pandas as pd
df = pd.read_csv('path/to/raw/data,csv')
And use the sample parameter there:
import pandas as pd
df = pd.read_csv('path/to/raw/data,csv')
# new code
if sample:
# sample 1%
df = df.sample(frac=0.01)
You can reproduce many bugs in a data pipeline with a portion of the data. The objective here is to speed up execution time to remove those bugs faster. Now that our pipeline runs with a sample by default, let’s rerun it:
ploomber build
To run with the entire dataset, execute ploomber build --help, and you’ll see the CLI argument to pass to switch the sample parameter.
Keep running your pipeline with a sample until it executes successfully.
A common source of error when executing notebooks is that the dependency version used to develop it in the first place (e.g., pandas 1.2) is different from the latest version (e.g., pandas 1.3). If any library introduces API-breaking changes, your pipeline will no longer run. Fixing dependency version issues is a trial and error process, so keep an eye on the types of errors and check the library’s documentation to look for changes in the API. If that’s the case, downgrade dependencies until you fix the issue:
# downgrade dependency
pip install pkg==version
# e.g., downgrade pandas 1.3 -> 1.2
pip install pandas==1.2
If you make such a change, remember to generate the requirements.lock.txt file again.
If you cannot trace back the error due to an API change, things will get more complicated, so let’s go to the next step.
Note: you can skip this step if the pipeline created in Step 1 is running correctly.
The goal of this step is to ensure that your notebook runs from start to finish. Most likely, the project doesn’t contain any tests, so the only reference that you have to know whether the code is doing what it’s supposed to do is the original analysis.ipynb notebook and the recorded outputs:
Open pipeline.ipynb in Jupyter and run it from top to bottom (ensure you turn sample=False to use the entire dataset). Then, on every cell, compare the output (if any) of analysis.ipynb and make sure it matches. Here’s where your judgment comes in because some lines of code may involve random processes (e.g., drawing random numbers); hence, the output won’t match exactly.
Continue until:
If a particular cell breaks, execute the following:
%debug
The previous command starts a debugging session from the latest raised exception.
> <ipython-input>(3)function()
1 def some_function(df):
2 # some code...
----> 3 do_something(df) # line that breaks
4 # more code...
5
%pdb enters the Python debugger; learning how to use it is invaluable for debugging Python code. Ploomber’s documentation contains a throughout example to use the debugger in data science projects. If you want to learn each of the available commands when you’re in debugging mode, check out the documentation.
Hopefully, by using the debugger, you’ll be able to find and fix the error.
This scenario is more challenging than the previous one because our code isn’t failing, so we don’t know where to debug. However, you may have some idea of where in the code things are failing; at each of those places, you can start a debugging session.
Say that the failing cell looks like this:
process_data_frame(df)
After careful examination, you determine that process_data_frame calls
some_function and that the error might be there. So you go to some_function
source code and edit it:
def some_function(df):
# some code
# let's say you think the error is here
from pdb import set_trace; set_trace()
do_something(df)
# more code...
Now, When calling process_data_frame(df), which in turn calls
some_function(df) and debugging session will start.
Debugging isn’t an easy task but using the debugger a much better than using print statements all over your code. Check out the debugging example in Ploomber’s documentation to learn a few tricks on debugging.
.ipynb to .pyAt this point, you should be able to execute your pipeline from start to finish without errors. This step and the upcoming ones ensure that your pipeline stays maintainable and stable.
Making small commits and testing on each git push is vital to ensure you know whenever your pipeline breaks. Furthermore, it’s much easier to find an issue introduced in a commit that modified ten lines of code than after twenty commits and hundreds of source code lines changed. Unfortunately, .ipynb are hard to manage because they’re JSON files containing code and output. For example, if you have a pipeline.ipynb file, edit a single cell, and commit the new version, you’ll see something like this:
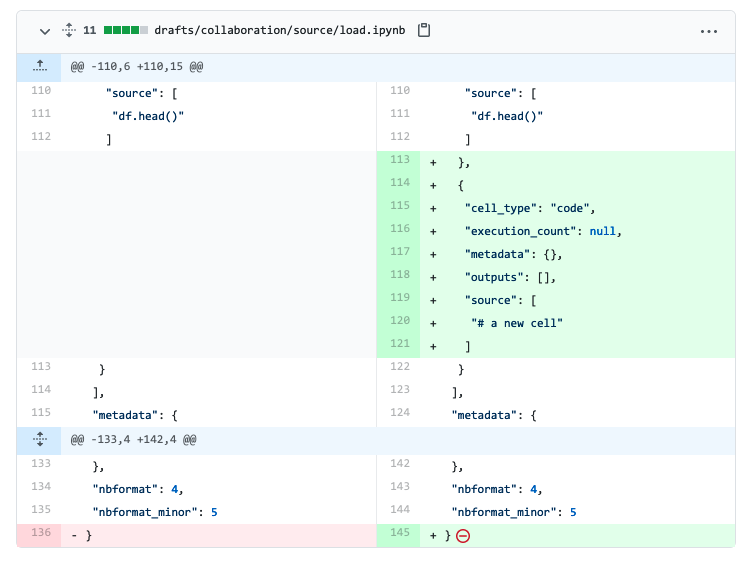
It’s hard to tell what changed with all the clutter. To solve the problem of diffing notebooks, we’ll convert our .ipynb files to .py using jupytext:
jupytext pipeline.ipynb --to py:percent
But do not worry! You can still open them as notebooks, thanks to jupytext’s Jupyter plug-in.
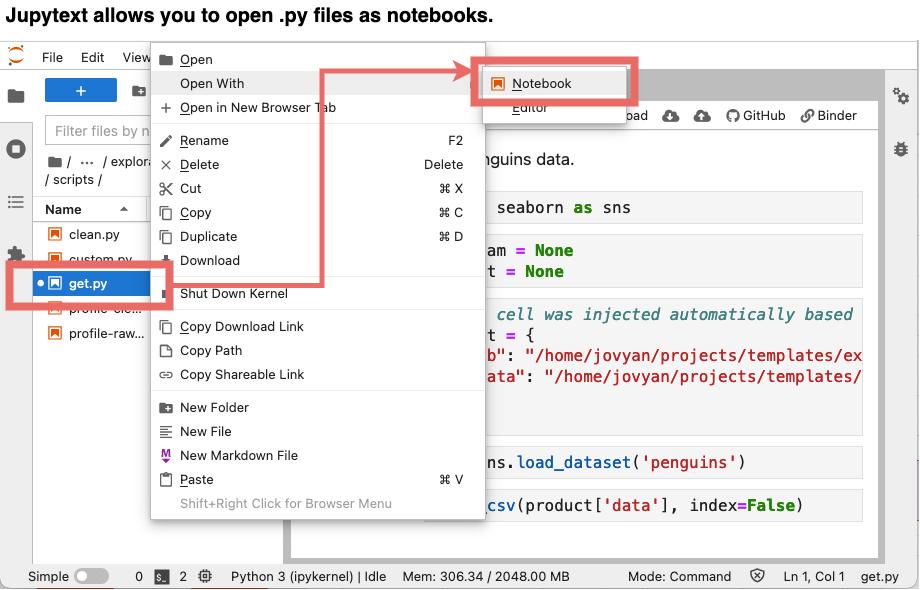
Note: Jupytext has many output formats, check out the documentation to learn more.
Once you convert your pipeline.ipynb to .py Update your pipeline.yaml file:
tasks:
# switch pipeline.ipynb for pipeline.py
- source: pipeline.py
product: output.ipynb
params:
sample: True
Ensure everything still works correctly:
ploomber build
If the pipeline runs, delete pipeline.ipynb.
So far, we’re able to execute our pipeline in a fresh environment: we install
dependencies and then execute ploomber build, but our pipeline is still
a monolith: all our code is in a single file. In the next part of this series,
we’ll address this issue and start splitting our logic in smaller steps.
To ensure you know when the second part is out, follow us on Twitter or susbcribe to our newsletter. See you soon!
Update: The second part is available here.
Seamless deployment for data scientists and developers. Ploomber handles infrastructure so you focus on building. Secure and scalable—from personal projects to enterprise apps. Support for Streamlit, Dash, Docker, and AI-powered applications. Because life's too short for deployment headaches.

